The **groupby()**function is one of the most useful functions when dealing with large dataframes in Pandas. A groupby operation typically involves a combination of splitting the object, applying a function, and combining the results.
If you are new to the **groupby()** function, however, things can be a little intimidating at first. So the aim of this article is to provide a gentle introduction to this simple, and yet extremely powerful function.
As usual, the best way to learn something is through examples, many of them. So let’s get started!
Loading the Sample DataFrame
Let’s load a dataframe with the following code snippet:
import pandas as pd
scores = {'Zone': ['North','South','South',
'East','East','West','West','West'],
'School': ['Rushmore','Bayside','Rydell',
'Shermer','Shermer','Ridgemont','Hogwarts','Hogwarts'],
'Name': ['Jonny','Joe','Jakob',
'Jimmy','Erik','Lam','Yip','Chen'],
'Math': [78,76,56,67,89,100,55,76],
'Science': [70,68,90,45,66,89,32,98]}
df = pd.DataFrame(scores, columns =
['Zone', 'School', 'Name',
'Science', 'Math'])
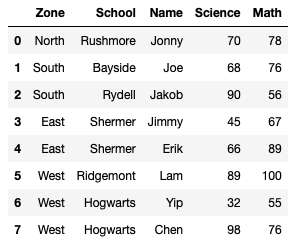
df
The dataframe (**df**) looks like this:
Calling groupby() with a string (name of column)
Let’s group the dataframe by **Zone**:
gp = df.groupby('Zone') # pass in a string to groupby()
for zone, group in gp:
print(zone)
print(group) # group is a dataframe
It should print out the following output:
East
Zone School Name Science Math
3 East Shermer Jimmy 45 67
4 East Shermer Erik 66 89
North
Zone School Name Science Math
0 North Rushmore Jonny 70 78
South
Zone School Name Science Math
1 South Bayside Joe 68 76
2 South Rydell Jakob 90 56
West
Zone School Name Science Math
5 West Ridgemont Lam 89 100
6 West Hogwarts Yip 32 55
7 West Hogwarts Chen 98 76
As you can see from the output, you are grouping the dataframe by **Zone**. The **groupby()** function in this example returns a **DataFrameGroupBy** object. To print out each zone and its associated grouping, you can use the for-in loop to iterate through the **DataFrameGroupBy** object. The **zone** variable in this case will take on the values of each zone, and the **group** variable will contain the rows associated with each zone (contained within a dataframe). To print out the **Name** of each student and his/her **Science** and **Math** scores, you can select the respective columns in the group dataframe:
gp = df.groupby('Zone')
for zone, group in gp:
print(zone)
print(group[['Name','Science','Math']])
The above modified statement prints the following output:
East
Name Science Math
3 Jimmy 45 67
4 Erik 66 89
North
Name Science Math
0 Jonny 70 78
South
Name Science Math
1 Joe 68 76
2 Jakob 90 56
West
Name Science Math
5 Lam 89 100
6 Yip 32 55
7 Chen 98 76
Calling groupby() with a list of strings (column names)
Suppose you now want to group by **Zone** and **School**, so now you call the **groupby()** function with a list of strings (containing the columns names):
gp = df.groupby(['Zone','School']) # pass a list to groupby()
for zone_school, group in gp:
print(zone_school)
print(group[['Name','Science','Math']])
#pandas #python #dataframes #series #group-by #function