Building a Seq2Seq network from scratch using Tensorflow and Keras
During quarantine I tried to learn how to speak French to keep myself occupied. This attempt was not successful, so instead I built a neural network to try and learn it for me.
To do this I used a seq2seq recurrent neural network with an attention layer, trained on the House and Senate Debates of the 36th parliament of Canada (found here). Attention based seq2seq models are used commonly throughout a wide range of tasks, in fact if you have ever used Siri or Google Translate chances are you have benefited from this kind of model.
But before I get into how we can build one ourselves, I thought it would be a good idea to quickly touch on some of the theory behind how a seq2seq model works- focusing on a couple of the key elements that allow these models to perform so well.
What is a seq2seq model?
A seq2seq model’s goal in regard to NLP is to essentially compute the probability of an output sequence of words when considering an input sequence of words. This is useful for machine translation as we may have a bunch of potential translations and we want to learn which sequence is best — eg the dog is big > the big is dog. Or we may need to choose a word that’s most appropriate for a given sequence — eg running late for work > jogging late for work.
For machine translation we will need to encode a sequence of words into a vector that is easily digestible by the model, and then have the model decode this vector into our target language.We could use one model to do both the encoding and decoding but problems arise when you consider the input length may not match the output length, for example “my mum loves France” translates to “ma maman aime la france” — needing an extra word. These output sequence lengths are not necessarily known beforehand.
This leads us onto seq2seq models. The idea being that you get one model — the encoder — to take a sequence of words and turn them into an encoder vector which represents all the information in the sentence you want to translate. Then you get a decoder that takes this vector and outputs the translated words using a softmax function.
First the encoder takes an input sequence and returns its own hidden state.When computing the encoders hidden states (ht) we only need to consider the current input (xt) and the previous steps hidden state (ht-1) so the equation looks something like this -
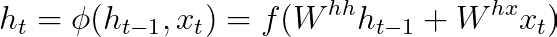
Then the decoder takes the last hidden vector of the encoder (c=ht), the previous hidden state (ht-1) and the previous predicted output word (yt-1). It may seem strange that we use both the previous predicted output word considering we calculate it from the last hidden vector of the encoder as well but using it allows the softmax to have an impact on current prediction (yt). Additionally rather than a probability distribution yt-1 actually gives a definitive answer on what the previous word was which helps prevent the model from repeating words. So overall our formula for the decoder hidden states looks something like this -
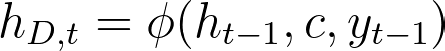
Now all we need to do is apply a softmax function at the end as in essence this will still be a multiclass classification problem but now our classes are each word in the target language at the next time step.
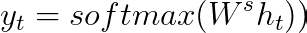
#nlp #python #data-science #seq2seq #tensorflow
