This blog covers another interesting machine learning algorithm called Decision Trees and it’s mathematical implementation.
At every point in our life, we make some decisions to proceed further. Similarly, this machine learning algorithm also makes the same decisions on the dataset provided and figures out the best splitting or decision at each step to improve the accuracy and make better decisions. This, in turn, helps in giving valuable results.
A decision tree is a machine learning algorithm which represents a hierarchical division of dataset to form a tree based on certain parameters.
Now, let’s discuss some basic terminologies related to a decision tree.
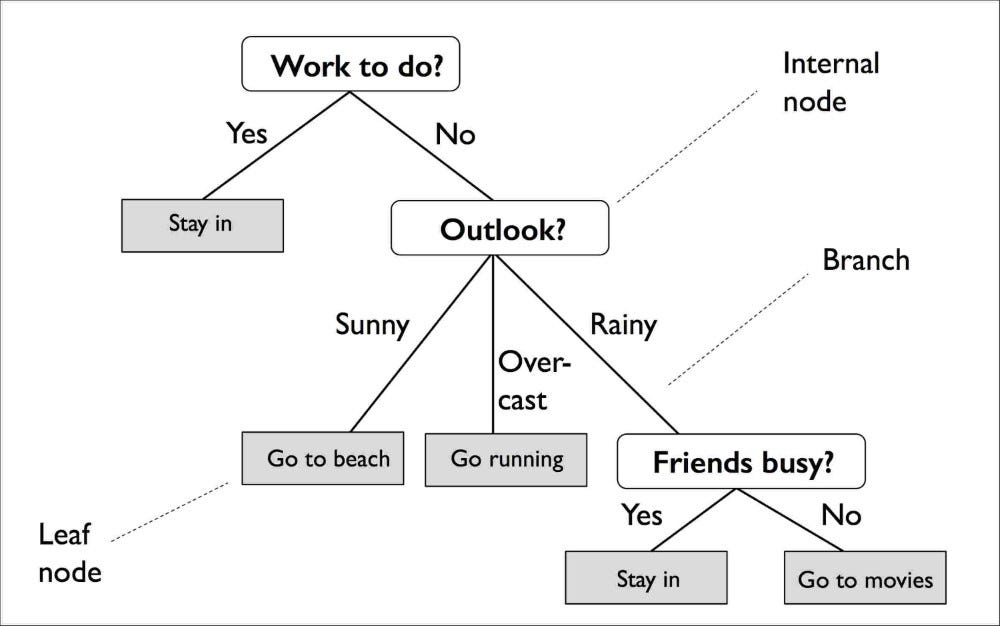
- Root Node: The starting node from where the first splitting occurs is called as Root Node. In other words, the topmost node is called as Root Node. In the above image, the “work to do” is the root node.
- Internal Nodes: The nodes which denote a test on an attribute is called an Internal Nodes. It doesn’t classify or holds a class label. It helps in further splitting to achieve leaf nodes. In the above image, “Outlook?” is an internal node.
- Leaf Nodes: The nodes which hold a class label is termed as leaf nodes. After this node, no further splitting can be done.
- Branch: The branch in a decision tree represents an outcome of the test done on an internal node.
#decision-tree #internity-foundation #information-gain #gini-impurity #machine-learning