In my recent article, I was investigating “pros” and “cons” between using DATETIME and DATETIME2 data types. This investigation appeared to be eye-opening for me, because, while reading documentation about those data types and potential drawbacks when using DATETIME2, I’ve discovered a whole new set of stuff I need to take care of!
What is Implicit Conversion?
In most simple words, Implicit conversion occurs when SQL Server needs to automatically convert some portion of data from one data type to another.
In some cases, when you are performing _JOIN_s, or filtering results using WHERE clause, you are comparing “apples” and “oranges” — therefore, SQL Server needs to convert “apples” to “oranges”, or vice versa.
Why is Implicit Conversion bad?
In order to resolve inconsistencies between data types, SQL Server must put additional effort and consume more resources. Thus, performance will suffer, leading to inefficient usage of indexes and extensive usage of CPU.
But, enough theory, let’s check how implicit conversion kills performance in reality.
Real use case
I have a table that contains data about chats initiated by customers. This table has around 8.6 million rows. One of the columns is “SourceID”, which is chat ID from the source system. In my table, this column is VARCHAR(20) type, despite all values contain only numbers.
I have a unique non-clustered index on the SourceID column, and index on the DatetmStartUTC column (this index includes all other foreign key columns), so let’s run few queries to check what’s happening in the background.
I’ve also turned on statistics for IO and time, to be able to compare results. Finally, I’ve turned on the Actual Execution Plan to get more insight into every specific step in query execution.
Query #1 AKA “Killer”
When someone performs simple data profiling within this table and see only numbers in SourceID column, it is completely expected to write a query like this:
DECLARE @sourceIDi INT = 8000000
SELECT sourceID
FROM factChat
WHERE sourceID >= @sourceIDi
SQL Server returns around 822.000 rows, which is approximately 10% of data in the whole table.
One would expect that SQL Server uses an index on SourceID, but let’s check if that’s the case:
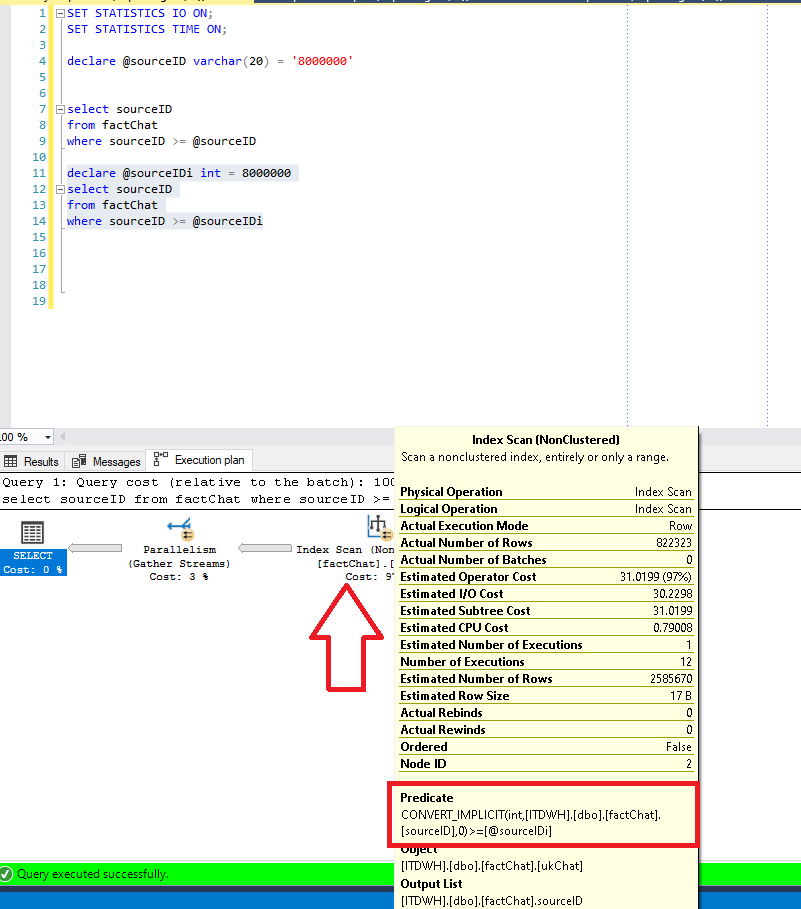
As we can notice, SQL Server uses our index, but instead of choosing to perform expected Index Seek operation, it scans the index. And if we hover over the Index Scan step, we will see in Predicate pane that implicit conversion occurred, since SQL Server had to apply data conversion behind the scenes during the query process.
#performance #sql-server #towards-data-science #sql #data #data analysis