So you, my dear Python enthusiast, have been learning Pandas and Matplotlib for a while and have written a super cool code to analyze your data and visualize it. You are ready to run your script that reads a huge file and all of a sudden your laptop starts making un ugly noise and burning like hell. Sounds familiar?
Well, I have got a couple of good news for you: this issue doesn’t need to happen anymore and you no, you don’t need to upgrade your laptop or your server.
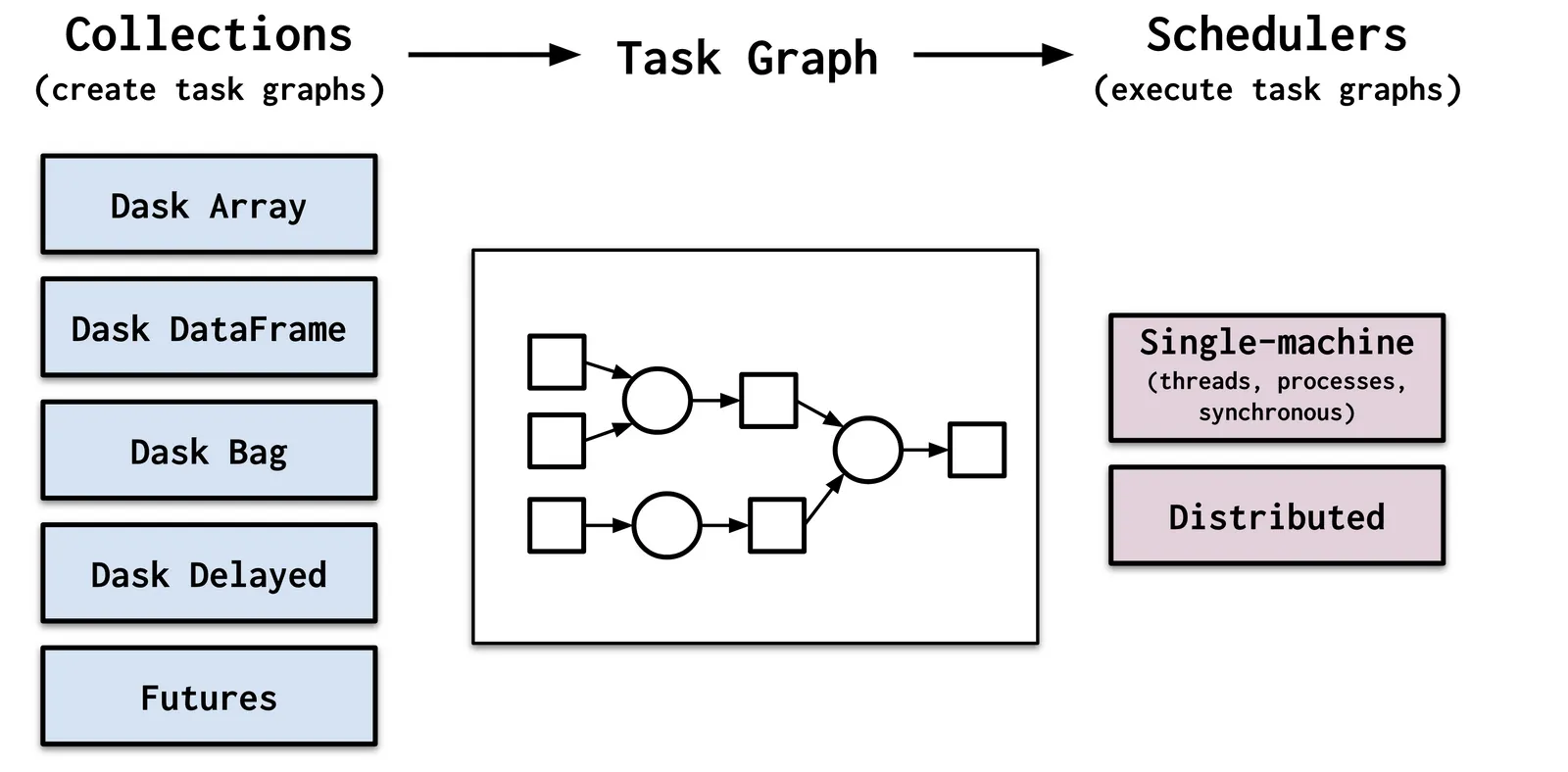
Introducing Dask:
Dask is a flexible library for parallel computing with Python. It provides multi-core and distributed parallel execution on larger-than-memory datasets. It figures out how to break up large computations and route parts of them efficiently onto distributed hardware.
A massive cluster is not always the right choice
Today’s laptops and workstations are surprisingly powerful and, if used correctly, can handle datasets and computations for which we previously depended on clusters. A modern laptop has a multi-core CPU, 32GB of RAM, and flash-based hard drives that can stream through data several times faster than HDDs or SSDs of even a year or two ago.
As a result, Dask can empower analysts to manipulate 100GB+ datasets on their laptop or 1TB+ datasets on a workstation without bothering with the cluster at all.
The project has been a massive plus for the Python machine learning Ecosystem because it democratizes big data analysis. Not only can you save money on bigger servers, but also it copies the Pandas API so you can run your Panda script changing very few lines of code.
#pandas