One of the first admonitions that a young Padawan gets together with access to git repositories is: “never use git push -f”. Since this is one of the hundreds of maxims that a novice software engineer needs to learn, no one takes the time to clarify why this should not be done. It’s like with babies and fire: “matches are not toys for children”, and that’s it. But we grow and develop both as people and as professionals, and one day the question “actually, why?” may arise.
I’ve heard that in some companies the ability to answer this question at an interview is a criterion for hiring for senior positions.
But to better understand the answer to it, you need to find out why rewriting history is bad?
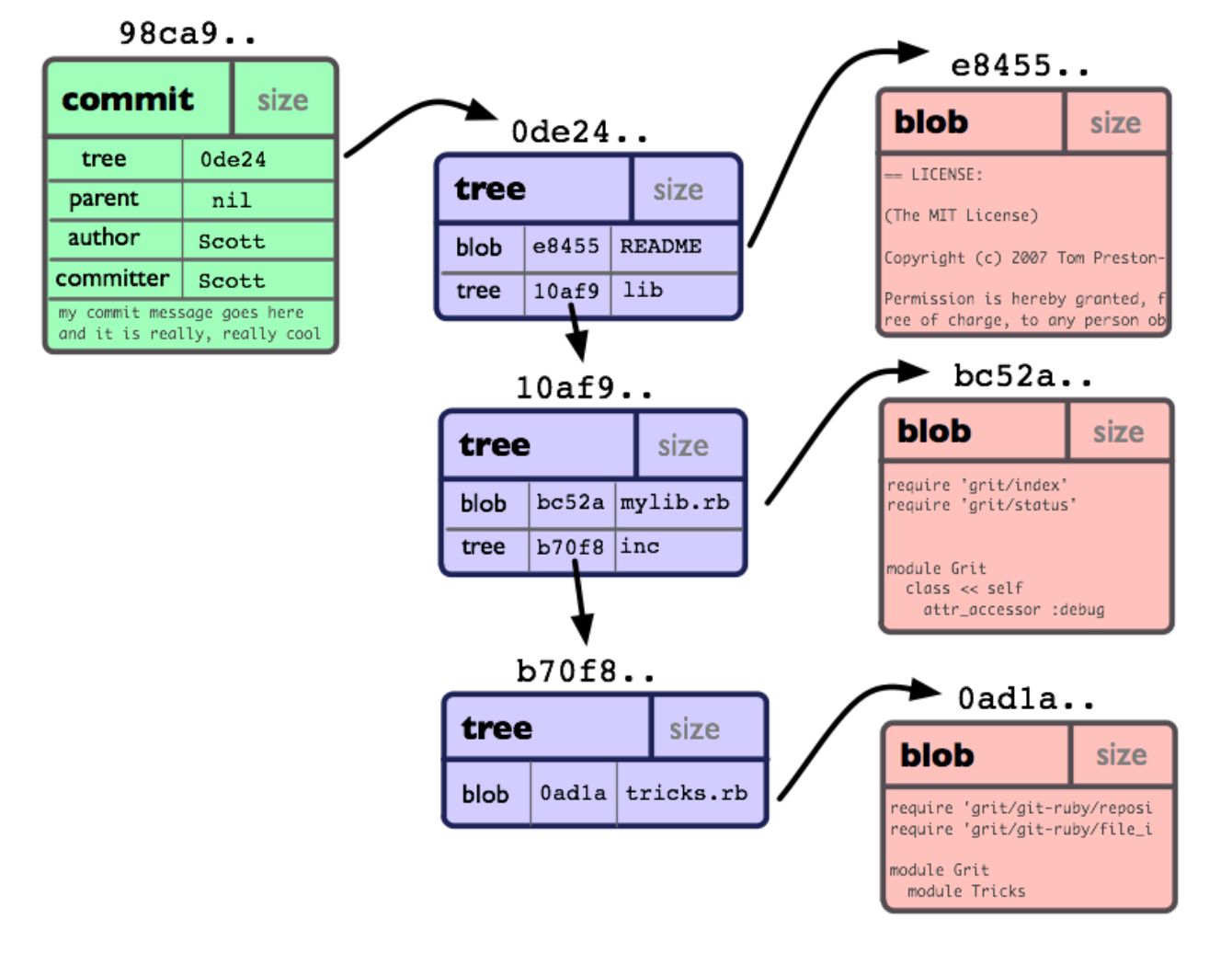
To do this, in turn, we need a quick excursion into the physical structure of a git repository. If you are pretty sure that you know everything about the repo structure, you can skip this part. But as for me, I learned a lot of new things in the process of clarification, and some old knowledge turned out to be not quite relevant.
At the lowest level, a git repo is a collection of objects and pointers to them. Each object has its own unique 40-character hash (20 hexadecimal bytes), which is calculated based on the contents of the object.
#git #github #gitlab #git-workflow #programming #coding
