How artificial intelligence has influenced our daily lives in the past decade is something we can only ponder about. From spam filtering to news clustering, computer vision applications like fingerprint sensors to natural language processing problems like handwriting and speech recognition, it is very easy to undermine how big a role AI and data science is playing in our day-to-day lives. However, with an exponential increase in amount of data our algorithms deal with, it is essential to develop algorithms which can keep pace with this rise in complexity. One such algorithm which has caused a notable change to the industry is the Adam Optimization procedure. But before we delve into it, first let us look at gradient descent and where it falls short.
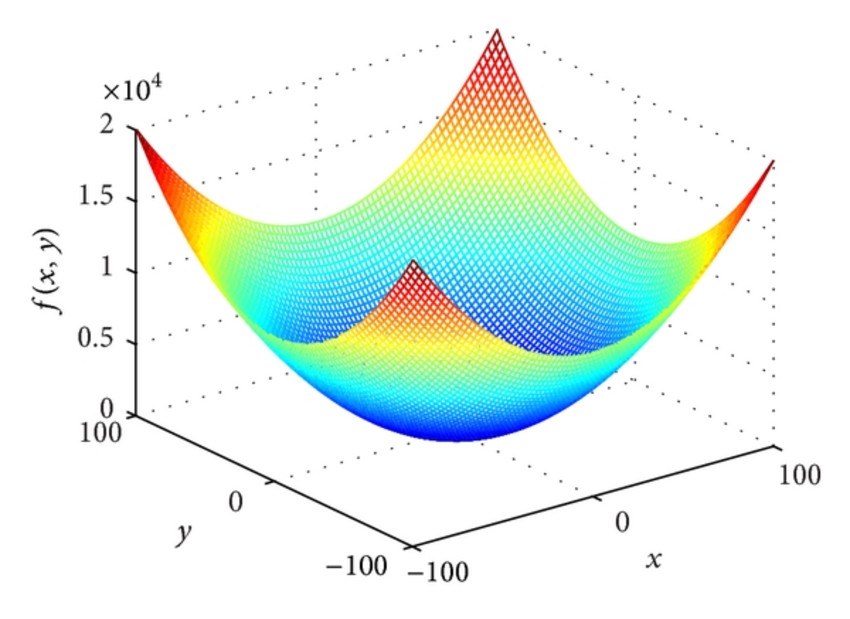
In case if you aren’t aware of what a cost function is, I would recommend you to go through this blog first, which serves as a great introduction to the topic:
Gradient Descent
Suppose we have a convex cost function of 2 input variables as shown above and our goal is to minimize its value and find the value of the parameters (x,y) for which f(x,y) is minimum. What the gradient descent algorithm does is, we start at a specific point on the curve and use the negative gradient to find the direction of steepest descent and take a small step in that direction and keep iterating till our value starts converging.
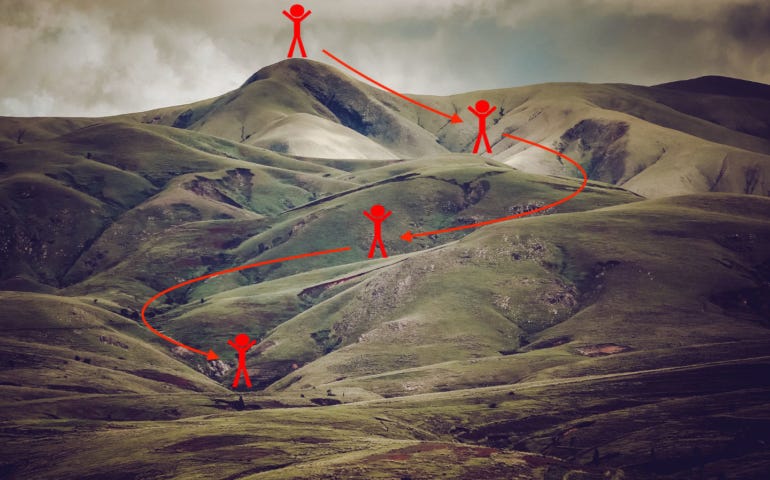
I personally find the above analogy to gradient descent very cool, a person starting from the top of a hill and climbing down by the path which enables him to decrease his altitude quickest.
#data-science #artificial-intelligence #deep-learning #data analysis
