Build your recommendation engine with the help of Python, from basic models to content-based and collaborative filtering recommender systems.
The purpose of this tutorial is not to make you an expert in building recommender system models. Instead, the motive is to get you started by giving you an overview of the type of recommender systems that exist and how you can build one by yo
In this tutorial, you will learn how to build a basic model of simple and content-based recommender systems. While these models will be nowhere close to the industry standard in terms of complexity, quality, or accuracy, it will help you to get started with building more complex models that produce even better results.
Recommender systems are among the most popular applications of data science today. They are used to predict the “rating” or “preference” that a user would give to an item. Almost every major tech company has applied them in some form. Amazon uses it to suggest products to customers, YouTube uses it to decide which video to play next on autoplay, and Facebook uses it to recommend pages to like and people to follow.
What’s more, for some companies like Netflix, Amazon Prime, Hulu, and Hotstar, the business model and its success revolves around the potency of their recommendations. Netflix even offered a million dollars in 2009 to anyone who could improve its system by 10%.
There are also popular recommender systems for domains like restaurants, movies, and online dating. Recommender systems have also been developed to explore research articles and experts, collaborators, and financial services. YouTube uses the recommendation system at a large scale to suggest you videos based on your history. For example, if you watch a lot of educational videos, it would suggest those types of videos.
But what are these recommender systems?
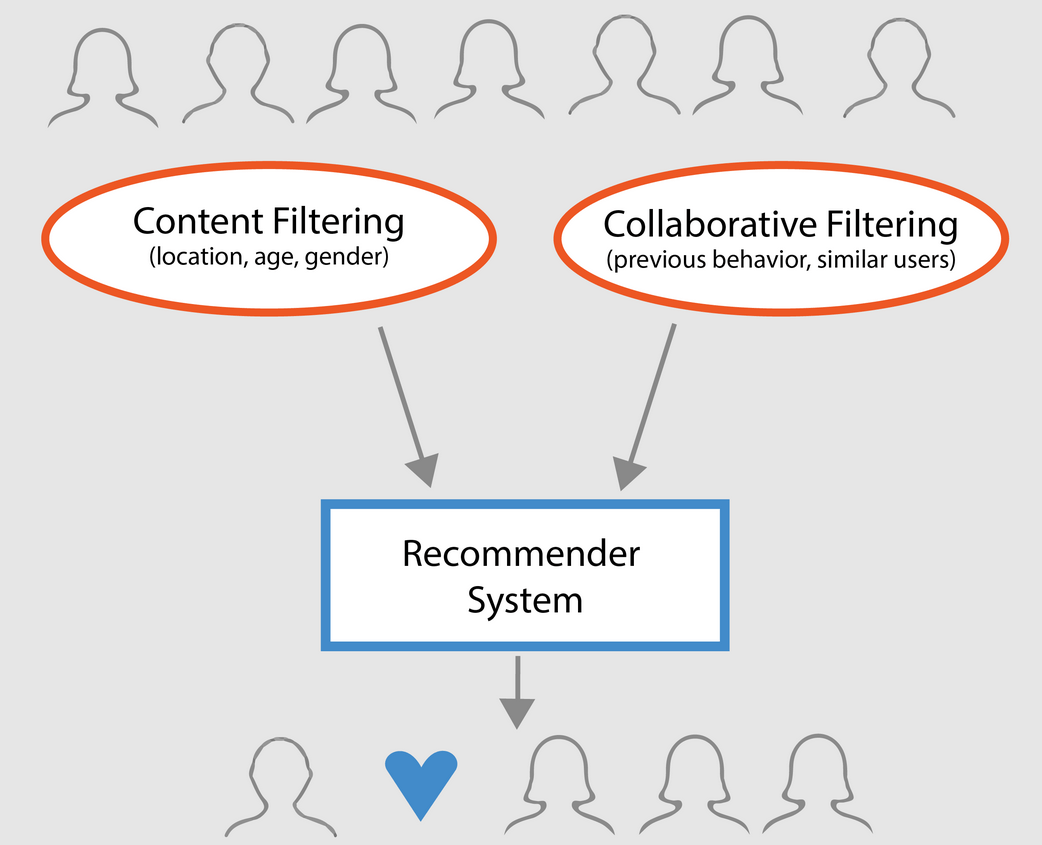
Broadly, recommender systems can be classified into 3 types:
- Simple recommenders: offer generalized recommendations to every user, based on movie popularity and/or genre. The basic idea behind this system is that movies that are more popular and critically acclaimed will have a higher probability of being liked by the average audience. An example could be IMDB Top 250.
- Content-based recommenders: suggest similar items based on a particular item. This system uses item metadata, such as genre, director, description, actors, etc. for movies, to make these recommendations. The general idea behind these recommender systems is that if a person likes a particular item, he or she will also like an item that is similar to it. And to recommend that, it will make use of the user’s past item metadata. A good example could be YouTube, where based on your history, it suggests you new videos that you could potentially watch.
- Collaborative filtering engines: these systems are widely used, and they try to predict the rating or preference that a user would give an item-based on past ratings and preferences of other users. Collaborative filters do not require item metadata like its content-based counterparts.
Simple Recommenders
As described in the previous section, simple recommenders are basic systems that recommend the top items based on a certain metric or score. In this section, you will build a simplified clone of IMDB Top 250 Movies using metadata collected from IMDB.
The following are the steps involved:
- Decide on the metric or score to rate movies on.
- Calculate the score for every movie.
- Sort the movies based on the score and output the top results.
#python #machine-learning #data-science
