If you want to make a head start in enterprise NLP, but have no clue about Spark, this article is for you. I have seen many colleagues wanting to step to this domain but disheartened due to the initial learning overhead that comes with Spark. It may seem inconspicuous at first glance since Spark code is a bit different than your regular Python script. However, Spark and Spark NLP basics aren’t really hard to learn. If you axiomatically accept this assertion, I will show you how easy the basics are and will provide a road map to pave the way to learn key elements, which will satisfy most use cases of an intermediate level practitioner. Due to impeccable modularity that comes with Spark NLP pipelines, for an average learner, -mark my words- two weeks will be enough to build basic models. Roll up your sleeves, here we start!
Why Spark NLP?
Supply and Demand is the answer: It Is The Most Widely Used Library In Enterprises! Here are a few reasons why. Common NLP packages today have been designed by academics and they favor ease of prototyping over runtime performance, eclipsing scalability, error handling, target frugal memory consumption and code reuse. Although some libraries like ‘the industrial-strength NLP library — spaCy’ might be considered an exception (since they are designed to get things done rather than doing research), they may fall short of enterprise targets when it comes to dealing with data in volume.
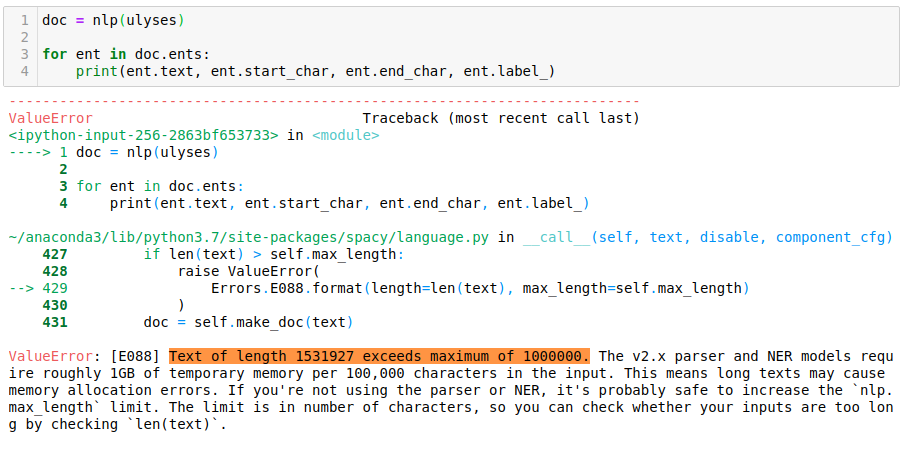
Usage of tools designed for research and smaller scale tasks cannot be handy
We are going to have a different strategy here. Rather than following the crowds in the routine, we will use basic libraries to brush up ‘basics’ and then jump directly to address the enterprise sector. Our final aim is to target the niche by building continental pipelines, which are impossible to resolve with standard libraries, albeit their capacity in their league.
#spark-nlp #spark