Zero Shot Learning (ZSL), aims at recognizing objects from unseen classes, it is about the ability of a learner to identify different classes from observed data without never having observed such type of data during the training phase.
We all know how taxing the process of collecting, annotating, and
labeling data for training purposes is. Therefore there are a lot of requirements/demands for methods to make use of methods that could classify instances from classes that are not present in training samples, especially in Videos.
In this article, I aim to provide an overall review of how ZLS, especially in Videos, reads and relates to classes available for training purposes using Visual and Semantic Embeddings.
The learner in ZSL reads the data and relates to the classes available from the training and does an error estimation to provide an accurate output. In simple terms, ZSL recognizes an action by its closest estimation to the available data class. Hence, the accuracy of the technique will be limited by the availability of data classes from the training model. To overcome this obstacle, ZSL makes use of both Visual Embedding Labels and Semantic Embedding Labels in tandem with the help of different mapping techniques.
Let us elaborate on what the above statement means:
Visual Embedding Labels: Visual Embedding is the ability to understand imagery and convert it into a machine-readable code. After training from a large data set of images, the model usually identifies different actions and tries to classify it into available classes to provide a result.
Semantic Embedding Labels: Semantic embedding is like Visual Embedding with the only difference that the model tries to read words instead of images and classify it after comparing it with the available data set.
Now how do both come into play when it comes to Zero-Shot Learning?
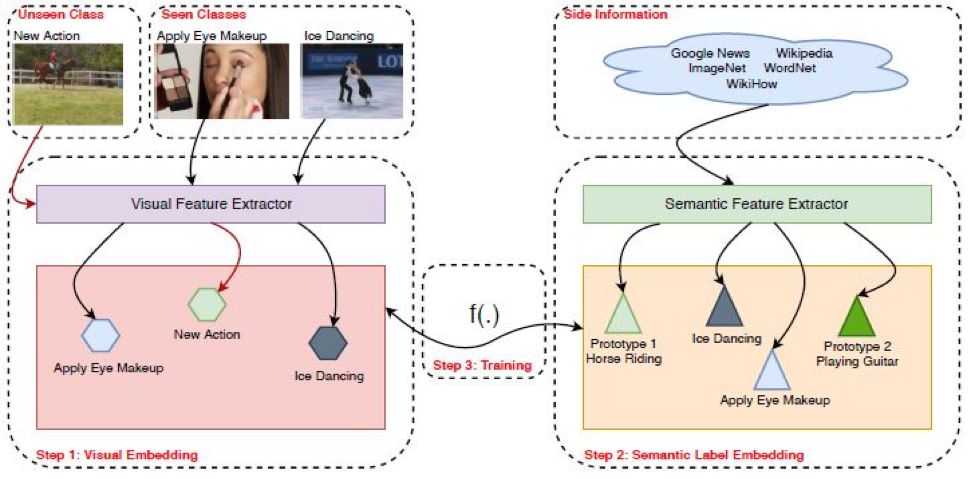
As illustrated in the picture above, what ZSL does is that it extracts both the visual and semantic information, identifies them in classes, and performs a mapping function. The mapping function outputs a class that is estimated against the available classes and the estimation with minimum error is identified as the unseen class.
#deep-learning #zero-shot-learning #deep learning