When working with geospatial data, it is often useful to find clusters of latitude and longitude coordinates either as a data preprocessing step for your machine learning model or as part of segmentation analysis. However, some frequently asked questions related to finding geospatial clusters include:
- Which clustering algorithm works best for your dataset?
- Which coordinates belong to which clusters?
- Where are the boundaries for each cluster/ how are coordinates being separated?
I recently worked on an Kaggle competition from 2017 to predict Taxi trip durations from mainly geospatial and temporal features (see post here). One of the preprocessing steps I did was to group locations into 20 clusters and find the number of pickups and dropoffs in each cluster to get a proxy for cluster density/traffic.
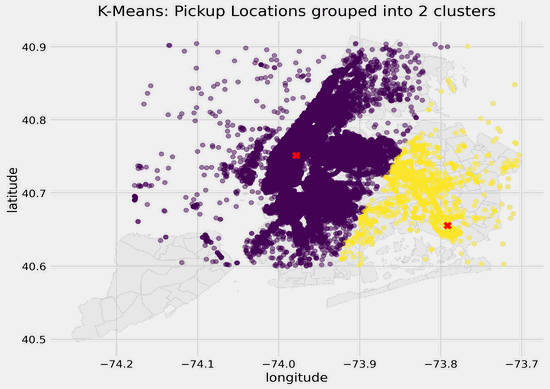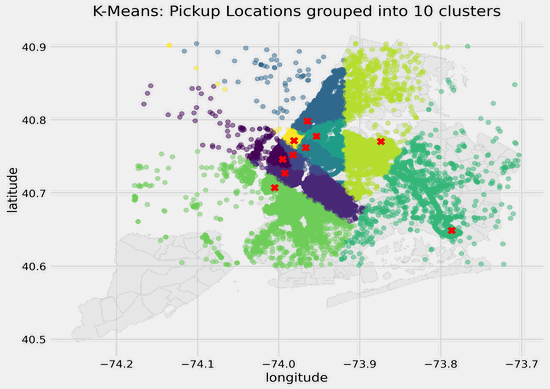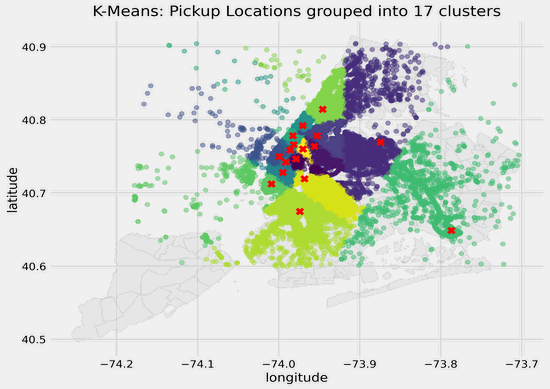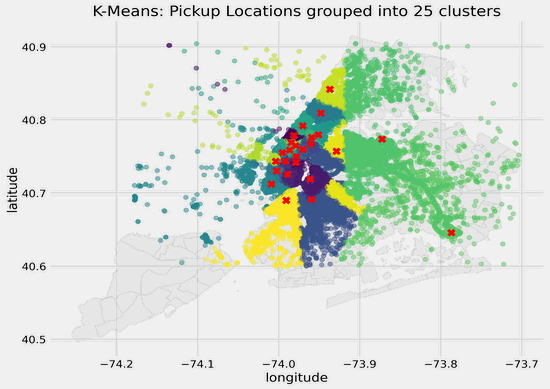
In this article, I will showcase how to visualize latitude and longitude coordinates and cluster centers on a map using matplotlib and geopandas. Below is what the different clusters look like for my dataset with different values of k ranging from 2 to 25 clusters. The different colored dots represent the pickup locations and which clusters they belong to as identified using K-Means clustering, and the red crosses represent the cluster centers.

Choosing a Clustering Algorithm
There are several unsupervised learning approaches to find clusters with similar attributes from your dataset, including K-Means clustering, agglomerative clustering and DBSCAN. Since I was working with a large dataset with almost 1.5 million data points, I chose to use scikit-learn’sMiniBatchKMeans, a version of K-Means clustering that uses minibatches to speed up the process.
One of the parameters in K-Means clustering is to specify the number of clusters (k). A popular method to find the optimal value of _k _is the elbow method, where you plot the sum of squared distances against values of k and choose the inflection point (point of diminishing returns).
ssd = []
for i in range(2, 26):
km = MiniBatchKMeans(n_clusters=i)
km.fit_predict(df_pickup_filtered)
ssd.append(km.inertia_)

The elbow method suggests that the optimal value of _k _for this dataset is 6. As NYC is a large city, is 6 clusters granular enough? To check, I will move on to visualize clusters with different values of _k _applied to this geospatial dataset.
#visualization #geopandas #geospatial #k-means #geospatial-data