In the last post, we explained the most used linear regression machine learning technique, the least-squares. We explained distinct approaches to multiple linear regressions and regressions with multiple outputs.
But we assumed that we use all variables in the regression, today we will explain some techniques to select only a subset of variables. We do that because of two reasons:
Reasons to use a subset selection
Prediction Accuracy
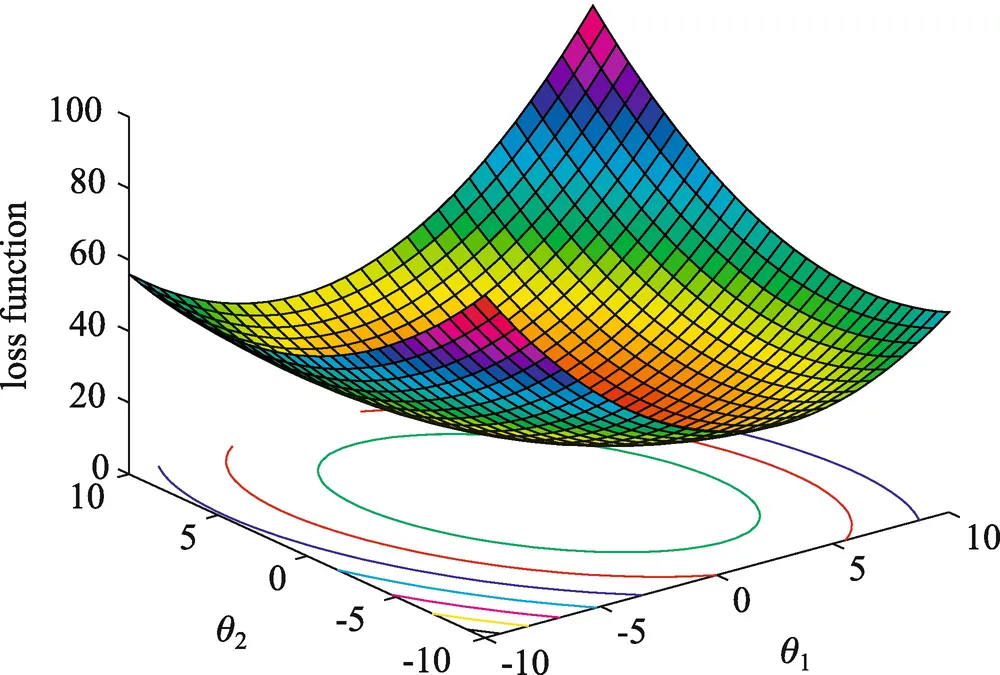
As we explained in the last post, the least-squares model minimizes the bias of the data, but not the variance. Here is where the bias-variance trade-off enters the game. Estimating a model, the expected prediction error at point x is:
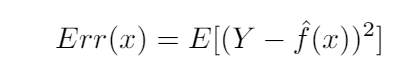
The error of prediction at a point x, self-generated.
We can decompose this error in three terms:
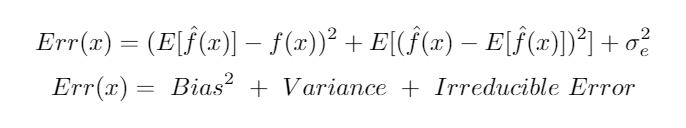
The error of prediction at point x decomposition, self-generated.
Here is where the bias-variance tradeoff appears, the bias and variance can be reduced to 0, but just in the world where data is perfectly predictable, it’s impossible to find in real-world data. So we have two errors to minimize and normally when we minimize the bias we increase the variance of our model.
- The bias is the error that you obtain from your classifier even with infinite training data, the error that you obtain with your assumptions on data, and the model used to predict it. This is due to your classifier being biased toward a particular kind of solution. In other words, bias is inherent to your model. (Undefitting)
- The **variance **is the error from sensitivity to small fluctuations in the training set. High variance can cause an algorithm to model the random noise in the training data, rather than the intended outputs. (Overfitting)
#mathematics #machine-learning #linear-regression #data-science #deep-learning