These are the lecture notes for FAU’s YouTube Lecture “Deep Learning”. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. If you spot mistakes, please let us know!
Navigation
Previous Lecture** / Watch this Video / Top Level / Next Lecture**Welcome back to deep learning! Today we want to talk a bit about gated recurrent units (GRUs), a simplification of the LSTM cell.

GRUs offer a simpler approach to long temporal contexts. Image source: imgflip.
So again a neural network: Gated recurrent units. So the idea here is that the LSTM is, of course, great, but it has a lot of parameters and it’s kind of difficult to train.

GRUs have comparable performance to LSTMs, but fewer parameters.
So, Cho came up with the gated recurrent unit and it was introduced in 2014 for statistical machine translation. You could argue it’s a kind of LSTM, but it’s simpler and it has fewer parameters.
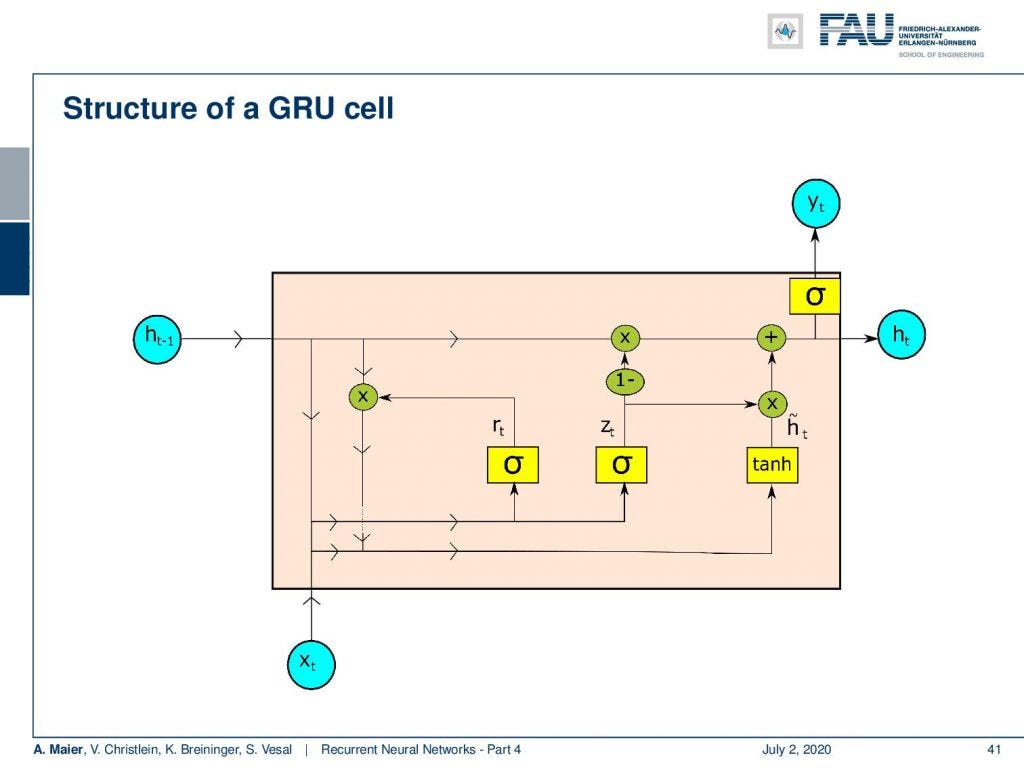
The structure of a GRU cell.
So this is the general setup. You can see we don’t have two different memories like in the LSTM. We only have one hidden state. One similarity to the LSTM is the hidden state flows only along a linear process. So, you only see multiplications and additions here. Again, as in the LSTM, we produce from the hidden state the output.

The main steps in the GRU workflow.
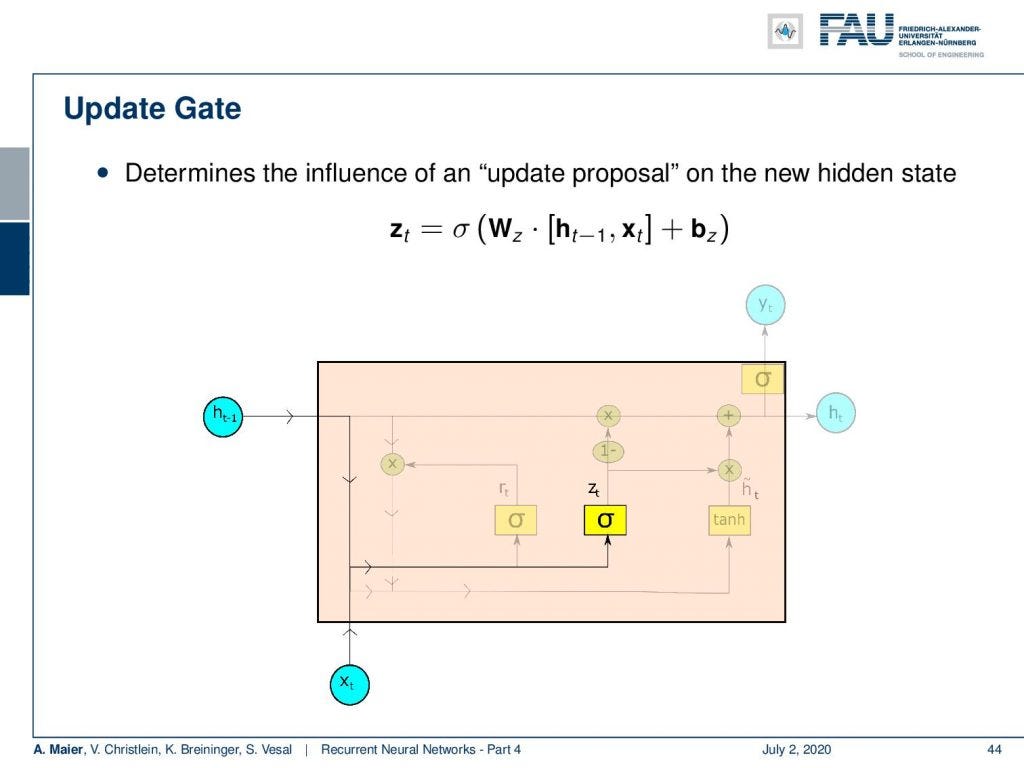
So let’s have a look into the ideas that Cho had in order to propose this cool cell. Well, it takes the concepts from the LSTM and it controls the memory by gates. The main difference is that there is no additional cell state. So, the memory only operates directly on the hidden state. The update of the state can be divided into four steps: There’s a reset gate that is controlling the influence of the previous hidden state. Then there is an update gate that introduces newly computed updates. So, the next step proposes an updated hidden state which is then used to update the hidden state.
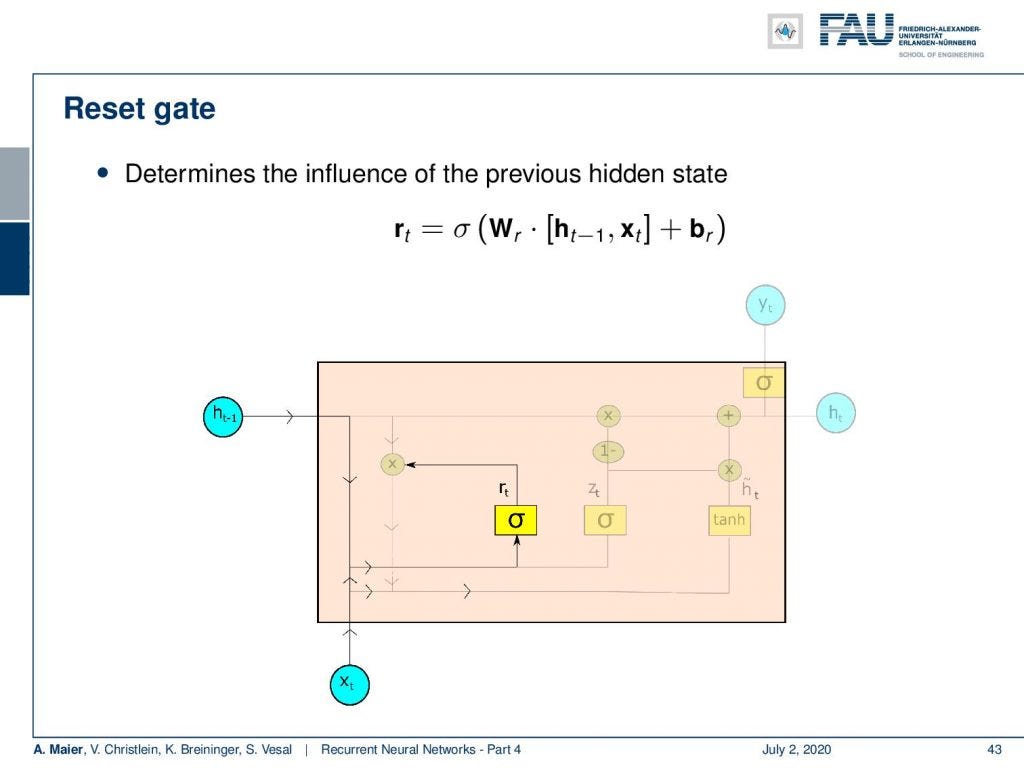
The reset gate.
So, how does this work? Well, first we determine the influence of the previous hidden state. This is done by a sigmoid activation function. We again have a matrix-type of update. We concatenate the input and the previous hidden state multiplied with a matrix and add some bias. Then, feed it to this sigmoid activation function which produces some reset value r subscript t.
#machine-learning #fau-lecture-notes #artificial-intelligence #data-science #deep-learning
