An alternative solution for flattening nested JSON files to a Pandas DataFrame with Jupyter-Notebook.
- Dataset belongs to ACN-Data
- My personal code along with the JSON file (acndata_sessions) can be found on my GitHub
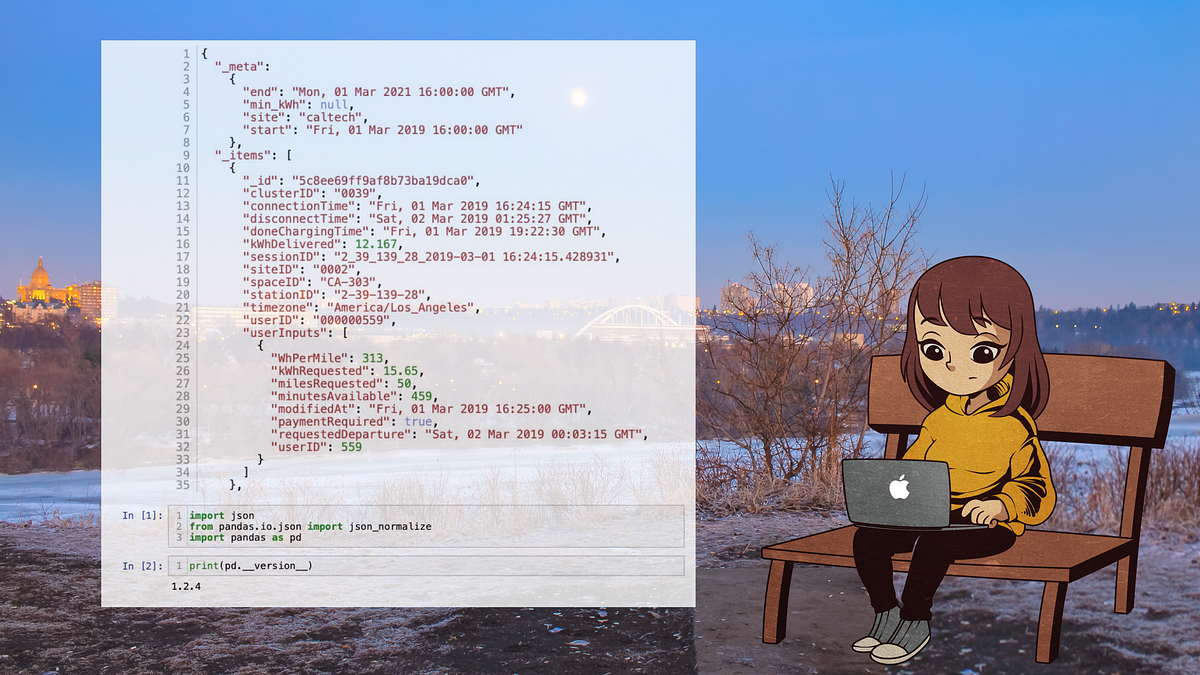
A few months ago I was tasked to work on a machine learning project and I came across a very interesting dataset. This dataset provided an insight to user expectations. It included a range of optional user inputs that increased the quality of the models I could train. I was invested into it’s potential and I added the JSON file to my Jupyter-Notebook.
To feel the weight of the cumbersome road ahead, I want to quickly describe what a JSON file is. JSON (JavaScript Object Notation) files are one of the most common data representation formats. They are language-independent and follow a very lightweight intuitive structure that was created to easily exchange data between human and machine. In order to achieve this, there are a few syntactical rules JSON files must follow:
- Storing data within name/value pairs
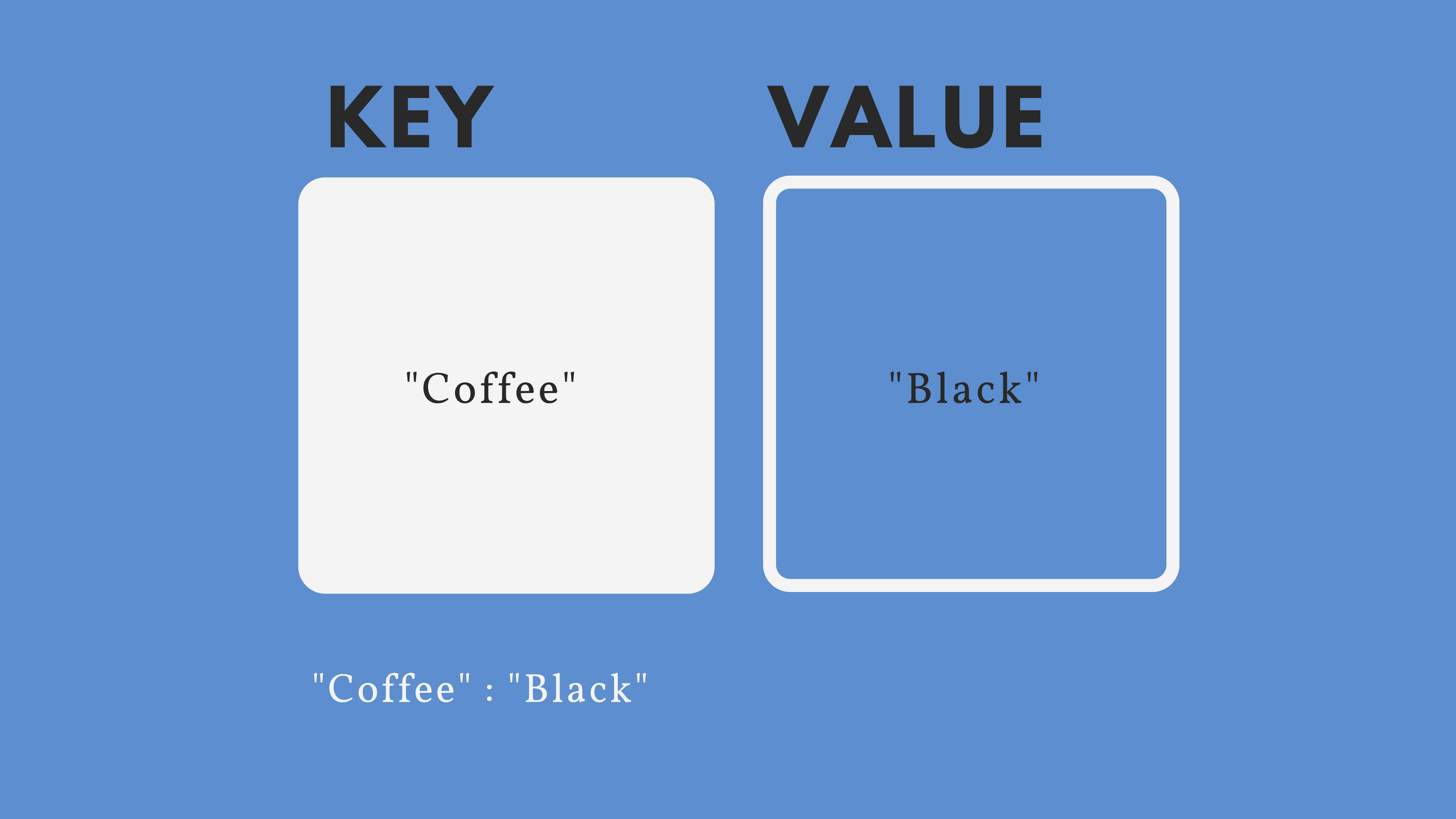
Photo by Author
#json #github #jupyter #pandas #python