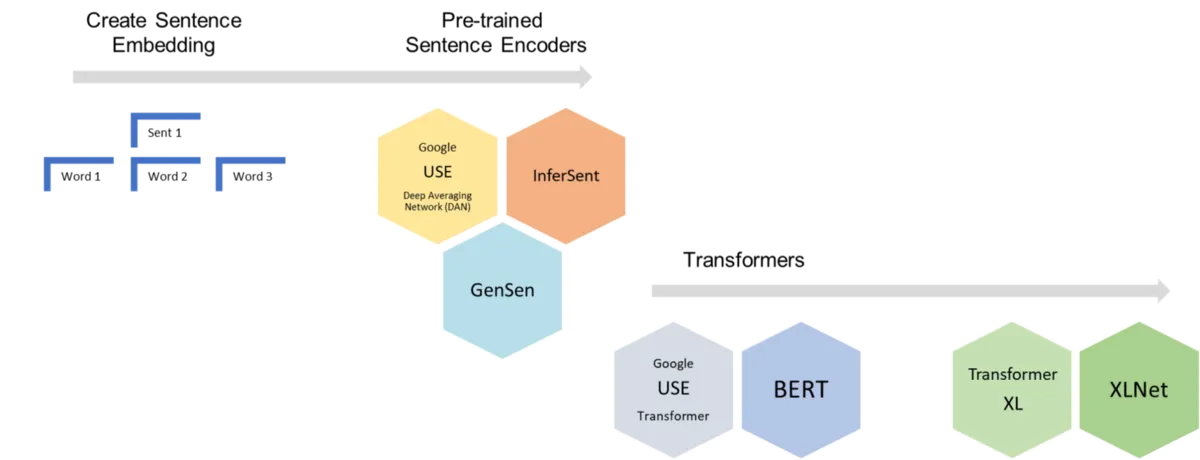
We often need to encode text data, including words, sentences, or documents into high-dimensional vectors. The sentence embedding is an important step of various NLP tasks such as sentiment analysis and extractive summarization. **A flexible sentence embedding library is needed to prototype fast and to tune for various contexts.**In the past, we mostly use encoders such as one-hot, term-frequency, or TF-IDF (a.k.a., normalized term-frequency). However, the semantic and syntactic information of words were not captured in these techniques. The recent advancements allow us to encode sentences or words in more meaningful forms. The word2vec technique and the BERT language model are two important ones. Note that, in this context, we use embedding, encoding, or vectorization interchangeably.The open-source sent2vec Python library allows you to encode sentences with high flexibility.You currently have access to the standard encoders in the library. More advanced techniques will be added in later releases. In this article, I want to introduce this library and share lessons that I learned in this context.
#data-science #machine-learning #open-source #artificial-intelligence #naturallanguageprocessing