These are the lecture notes for FAU’s YouTube Lecture “Deep Learning”. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. Try it yourself! If you spot mistakes, please let us know!
Navigation
Previous Lecture** / Watch this Video / Top Level / Next Lecture**

Reinforcement learning PacMac. Image created using gifify. Source: YouTube.
Welcome back to deep learning! So, today we want to discuss a little bit about this so-called Markov decision process which is the fundament of reinforcement learning.

Limitations of multi-armed bandits. Image under CC BY 4.0 from the Deep Learning Lecture.
I brought a couple of slides for you. We can see here what we are actually talking about. The topic is now reinforcement learning. Really, we want to learn how to play games. The key element will be the Markov decision process. So, we have to extend the multi-armed bandit problem that we talked about in the previous video. We have to introduce a state ssubscript t of the world. So, the world now has a state. The rewards also depend on the action and the state of the word. So, depending on the state of the world, actions may produce a very different reward. We can encode this again in a probability density function as you can see here on the slide. What else? Well, this setting now is known as the contextual bandit. In the full reinforcement learning problem also the actions influence the state. So, we will see whatever action I take, it will also have an effect on the state and this may also be probabilistic.
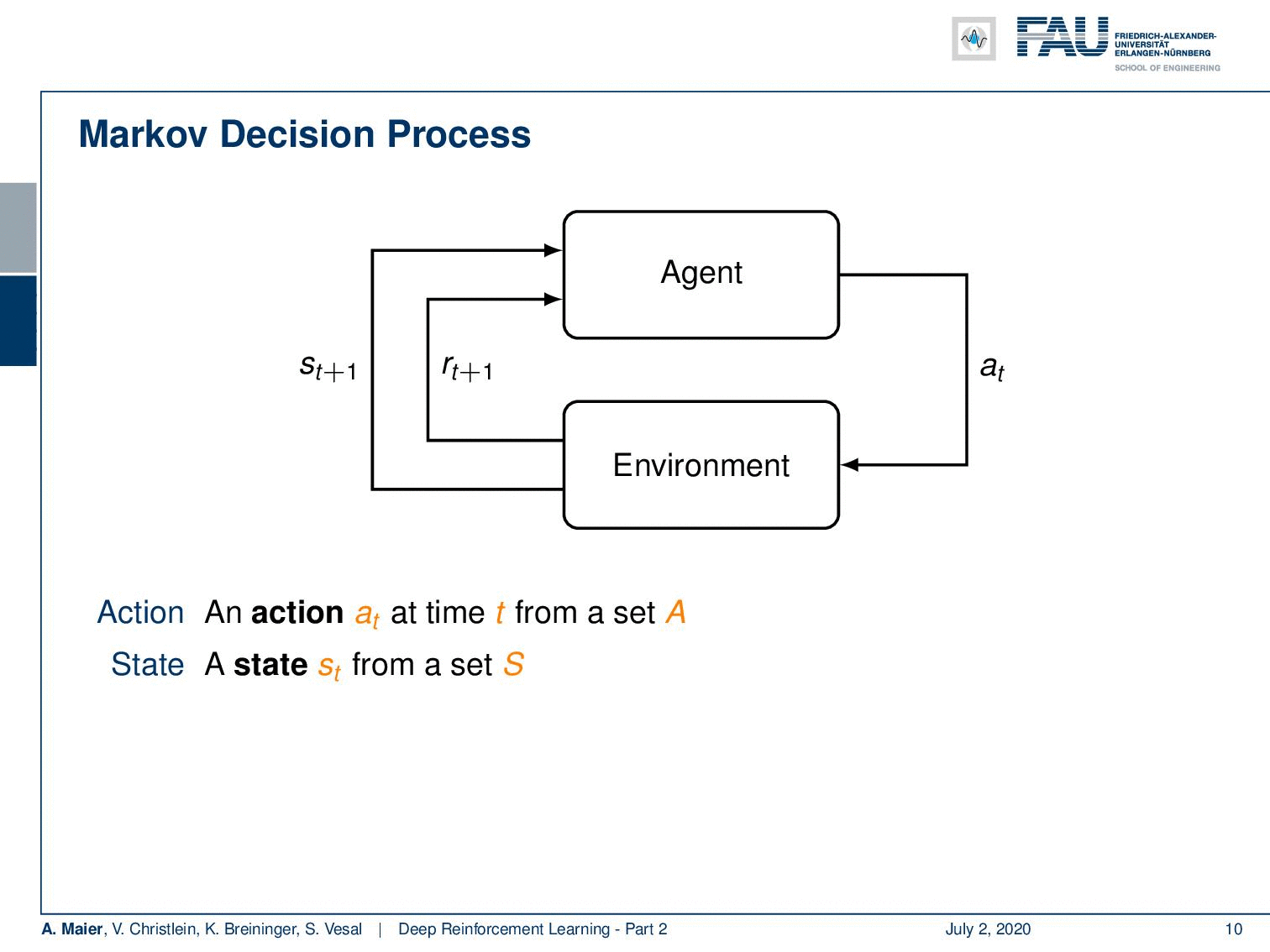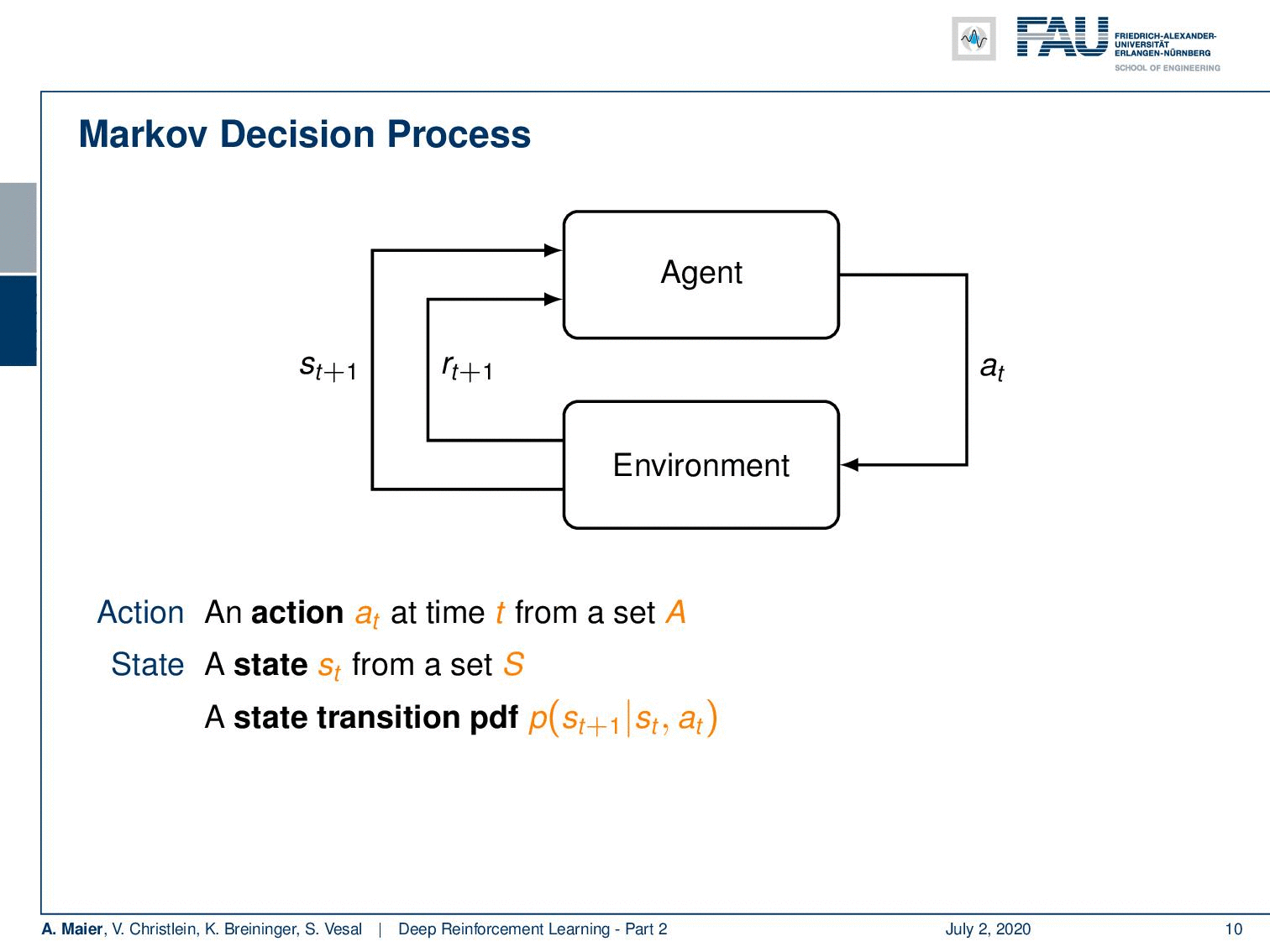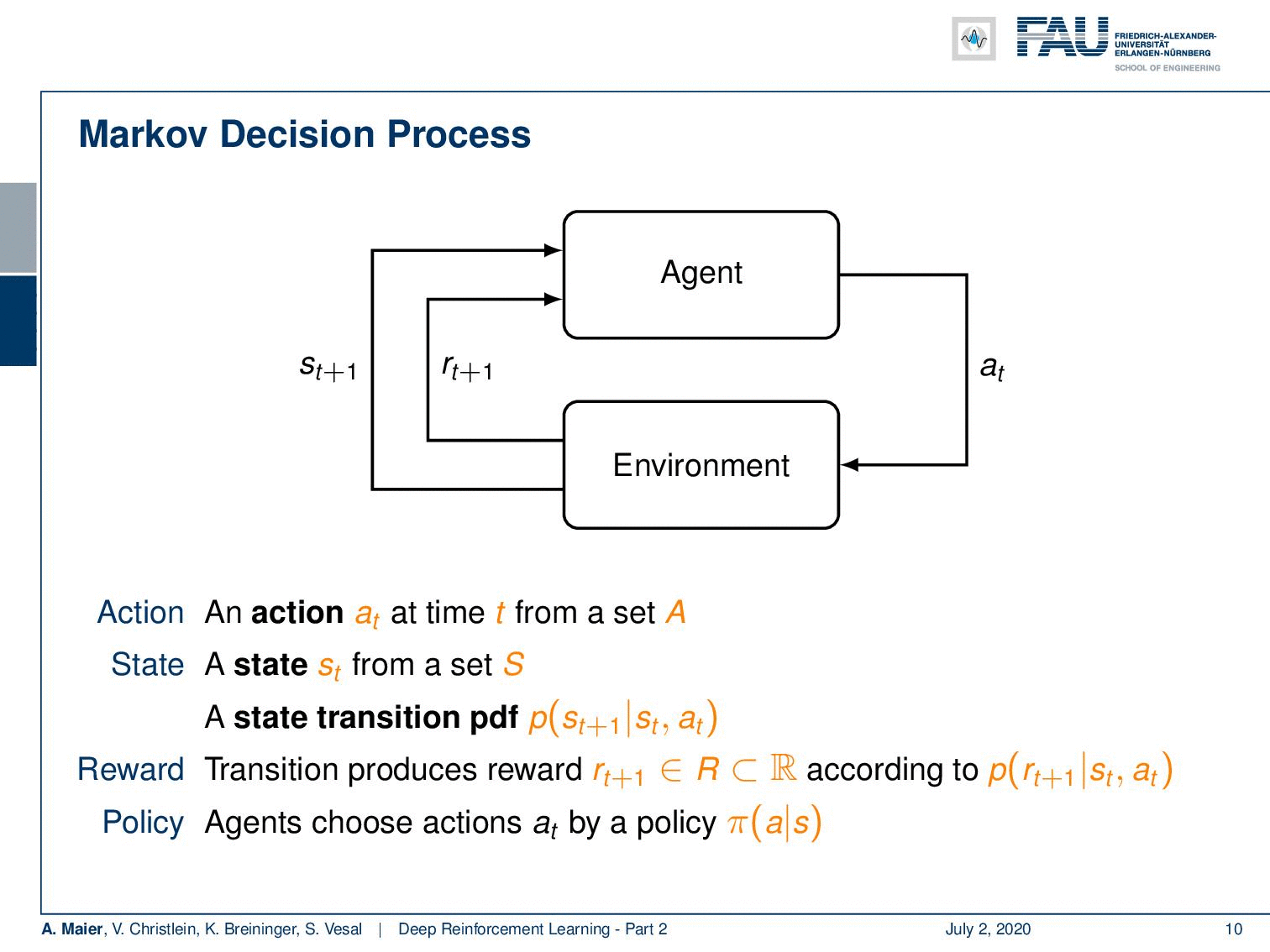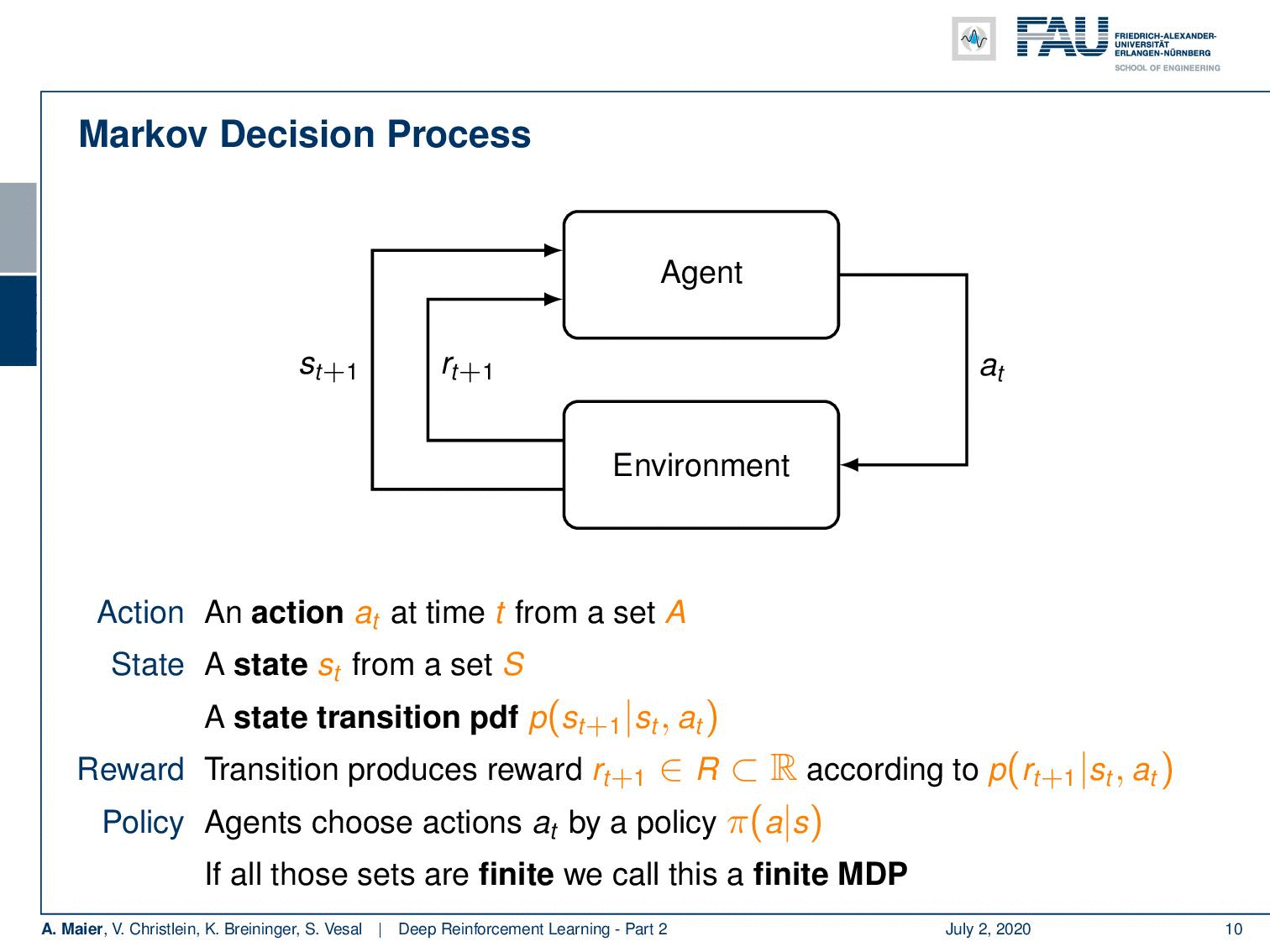
The Markov Decision Process. Image under CC BY 4.0 from the Deep Learning Lecture.
So, we can describe it in another probability density function. This then leads us to the so-called Markov decision process. Markov decision processes, they take the following form: You have an agent, and the agent here on top is doing actions a subscript t. These actions have an influence on the environment which then generates rewards as in the multi-armed bandit problem. It also changes the state. So now, our actions and the state are in relation to each other and they are of course dependent. Thus, we have a state transition probability density function that will cause the state to be altered depending on the previous state and the action that was taken. This transition also produces a reward and this reward is now dependent on the state and the action. Otherwise, it’s very similar to what we’ve already seen in the multi-armed bandit problem. Of course, we need policies, and the policies now also get the dependency on the state because you want to look into the state in order to pick your action and not just rely on the prior knowledge to choose the actions independent of the state. So, all of them are expanded accordingly. Now, if all of these sets are finite this is a finite Markov decision process. If you look at this figure, you can see this is a very abstract way of describing the entire situation. The agent is essentially the system that chooses the actions and designs the actions. The environment is everything else. So, for example, if you were to control a robot, the robot itself would probably be part of the environment as the location of the robot is also encoded in the state. Everything that can be done by the agent is merely designing actions. The knowledge about the current situation is encoded in the state.

#data-science #deep-learning #fau-lecture-notes #artificial-intelligence #machine-learning #deep learning
