Table variables can cause performance issues with joins when they contain a large number of rows. In SQL Server 2019, Microsoft has improved how the optimizer works with table variables which can improve performance without making changes to your code. In this article, Greg Larsen explains how this feature works and if it really does make a difference.
You probably have heard that table variables work fine when the table variable only contains a small number of records, but when the table variable contains a large number of records it doesn’t perform all that well. A solution for this problem has been implemented in version 15.x of SQL Server (Azure SQL Database and SQL Server 2019) with the rollout of a feature called Table Variable Deferred Compilation
_Table Variable Deferred Compilation _is one of many new features to improve performance that was introduced in the Azure SQL Database and SQL Server 2019. This new feature was included in the _Intelligent Query Processing _(IQP). See Figure 1 for a diagram that shows all the IQP features introduced in Azure SQL Database and SQL Server 2019, as well as features that originally were part of the Adaptive Query Processing feature included in the older generation of Azure SQL Database and SQL Server 2017.
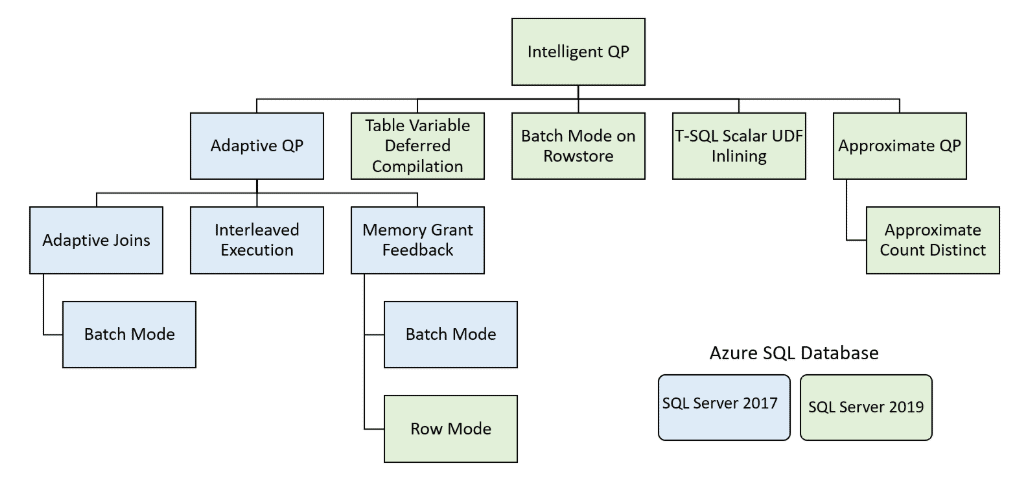
Figure 1: Intelligent Query Processing
In releases of SQL Server prior to 15.x, the database engine used a wrong assumption on the number of rows that were in a table variable. Because of this bad assumption, the execution plan that was generated didn’t work too well when a table variable contained lots of rows. With the introduction of SQL Server 2019, the database engine now defers the compilation of a query that uses a table variable until the table variable is used the first time. By doing this, the database engine can more accurately identify cardinality estimates for table variables. By having more accurate cardinality numbers, queries that have large numbers of rows in a table variable will perform better. Those queries will need to be running against a database with a database compatibility level set to 150 (version 15.x of SQL Server) to take advantage of this feature. To better understand how deferred compilation improves the performance of table variables that contain a large number of rows, I’ll run through an example, but first, I’ll discuss what is the problem with table variables in versions of SQL Server prior to version 15.x.
What is the Problem with Table Variables?
A table variable is defined using a DECLARE statement in a batch or stored procedure. Table variables don’t have distribution statistics and don’t trigger recompiles. Because of this, SQL Server is not able to estimate the number of rows in a table variable like it does for normal tables. When the optimizer compiles code that contains a table variable, prior to 15.x, it assumes a table is empty. This assumption causes the optimizer to compile the query using an expected row count of 1 for the cardinality estimate for a table variable. Because the optimizer only thinks a table variable contains a single row, it picks operators for the execution plan that work well with a small set of records, like the NESTED LOOPS operator for a JOIN operation. The operators that work well on a small number of records do not always scale well when a table variable contains a large number of rows. Microsoft documented this problem and recommends that temp tables might be a better choice than using a table variable that contains more than 100 rows. Additionally, Microsoft even recommends that if you are joining a table variable with other tables that you consider using the query hint RECOMPILE to make sure that table variables get the correct cardinality estimates. Without the proper cardinality estimates queries with large table variables are known to perform poorly.
With the introduction of version 15.x and the _Table Variable Deferred Compilation _feature, the optimizer delays the compilation of a query that uses a table variable until just before it is used the first time. This allows the optimizer to know the correct cardinality estimates of a table variable. When the optimizer has an accurate cardinality estimate, it has a good chance at picking execution plan operators that perform well for the number of rows in a table variable. In order for the optimizer to defer the compilation, the database must have its compatibility level set to 150. To show how deferred compilation of table variables work, I’ll show an example of this new feature in action.
#homepage #performance #performance monitor