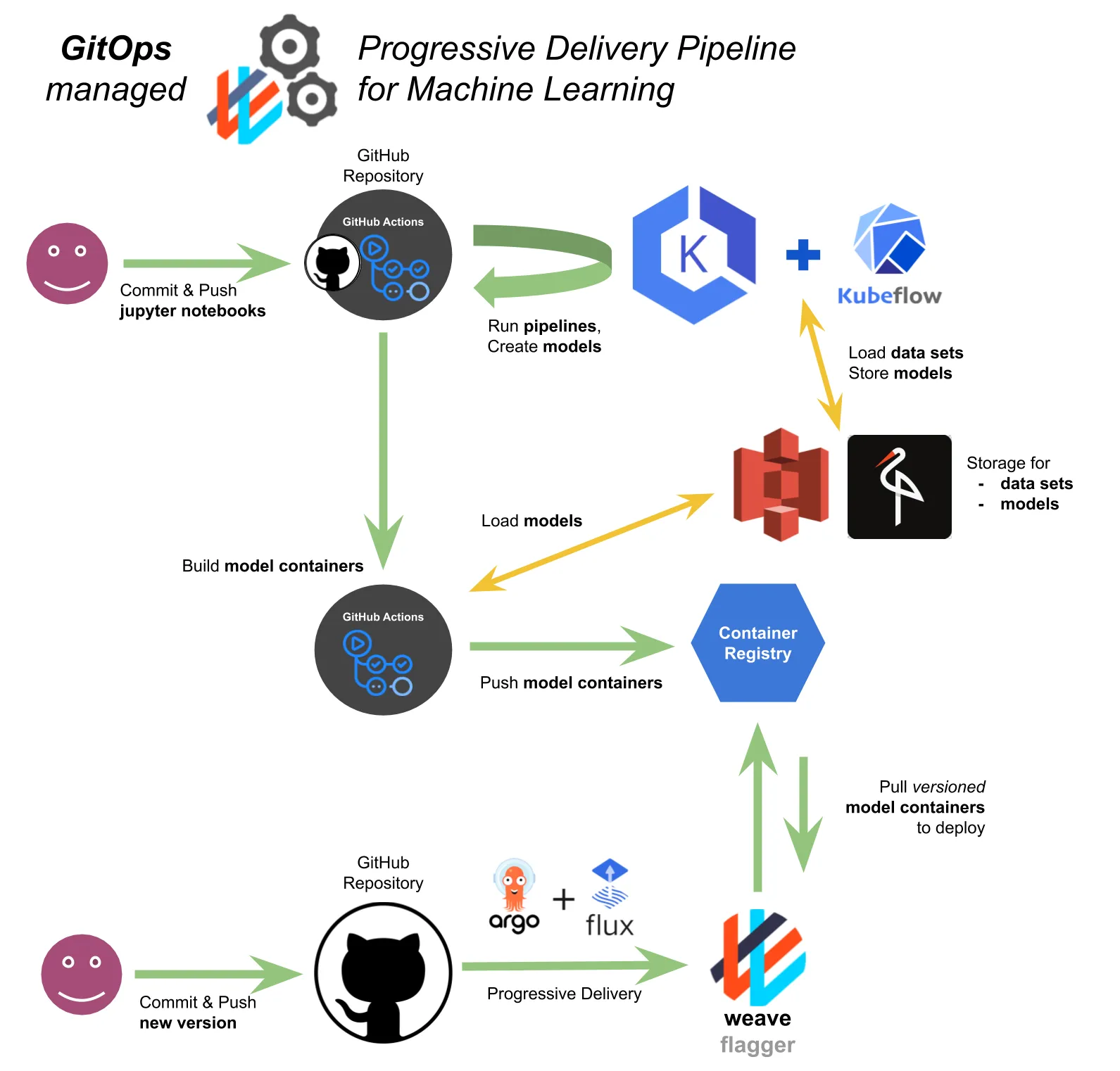
Kubeflow is an end-to-end machine learning platform on Kubernetes that provides components and rich features to compose machine learning pipelines. The new release, v1.3, came out recently, and you can deploy the new release on the IBM Kubernetes Service. The deployment involves Kubernetes cluster creation, local environment setup, deployment, and configuration, and if you are not familiar with these operations, they can look intimidating. One mistake in these procedures can lead to a painful debugging, reconfiguration, and even scrap and redo. Don’t worry, we’ve got you. Resources to lower the barrier for you: IBM Cloud Schematics to deploy multi-user Kubeflow v1.3, which integrates with App ID as a login mechanism, and an Auto-Kubeflow repository.
The Git repository provides a convenient approach for deploying Kubeflow v1.3 on IBM Cloud. It leverages IBM Cloud Schematics to do resource provisioning, including the Kubernetes cluster service and App ID. It finishes the deployment and configuration with an Ansible playbook. After clicking the Apply button on the Schematics service, you just sit back, relax, and wait for the deployment to complete automatically. When it finishes, a fully functional multi-user Kubeflow environment will be read for you. Currently, you can find two configurations for the Kubeflow deployment inside the repo:
- Classic: Run your cluster with native subnet and VLAN networking on a classic infrastructure
- VPC Gen 2: Create a fully customizable, software-defined virtual network with superior isolation using IBM Cloud VPC
#artificial intelligence #devops #ibm cloud #kubernetes