This article goes through the implementation of Graph Convolution Networks (GCN) using Spektral API, which is a Python library for graph deep learning based on Tensorflow 2. We are going to perform Semi-Supervised Node Classification using CORA dataset, similar to the work presented in the original GCN paper by Thomas Kipf and Max Welling (2017).
If you want to get basic understanding on Graph Convolutional Networks, it is recommended to read the first and the second parts of this series beforehand.
Dataset Overview
CORA citation network dataset consists of **2708 nodes, **where each node represents a document or a technical paper. The node features are bag-of-words representation that indicates the presence of a word in the document. The vocabulary — hence, also the node features — contains **1433 **words.

Illustration of bag-of-words as node features, via source
We will treat the dataset as an undirected graph where the edge represents whether one document cites the other or vice versa. There is no edge feature in this dataset. The goal of this task is to classify the nodes (or the documents) into 7 different classes which correspond to the papers’ research areas. This is a single-label multi-class classification problem withSingle Mode data representation setting.
This implementation is also an example of Transductive Learning, where the neural network sees all data, including the test dataset, during the training. This is contrast to Inductive Learning — which is the typical Supervised Learning — where the test data is kept separate during the training.
Text Classification Problem
Since we are going to classify documents based on their textual features, a common machine learning way to look at this problem is by seeing it as a supervised text classification problem. Using this approach, the machine learning model will learn each document’s hidden representation only based on its own features.
Illustration of text classification approach on a document classification problem (image by author)
This approach might work well if there are enough labeled examples for each class. Unfortunately, in real world cases, labeling data might be expensive.
What is another approach to solve this problem?
Besides its own text content, normally, a technical paper also cites other related papers. Intuitively, the cited papers are likely to belong to similar research area.
In this citation network dataset, we want to leverage the citation information from each paper in addition to its own textual content. Hence, the dataset has now turned into a network of papers.
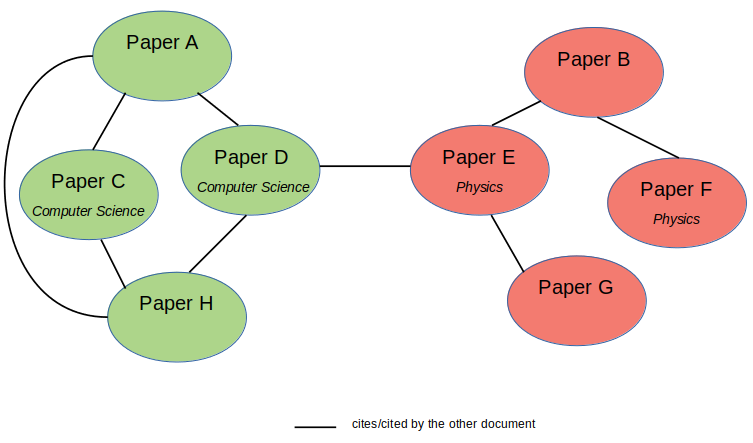
Illustration of citation network dataset with partly labeled data (image by author)
Using this configuration, we can utilize Graph Neural Networks, such as Graph Convolutional Networks (GCNs), to build a model that learns the documents interconnection in addition to their own textual features. The GCN model will learn the nodes (or documents) hidden representation not only based on its own features, but also its neighboring nodes’ features. Hence, we can reduce the number of necessary labeled examples and implement semi-supervised learning utilizing the Adjacency Matrix (A)or the nodes connectivity within a graph.
Another case where Graph Neural Networks might be useful is when each example does not have distinct features on its own, but the relations between the examples can enrich the feature representations.
#machine-learning #neural-networks #deep-learning #data-science #artificial-intelligence #deep learning