Overfitting is an issue that occurs when a model shows high accuracy in predicting training data (the data used to build the model), but low accuracy in predicting test data (unseen data that the model has not used before).
This can particularly be a problem when it comes to using small datasets in the course of building a neural network. It is possible for the neural network to be of such a size that it “overtrains” on the training data — and therefore performs poorly when it comes to predicting new data.
Role of Dropout in Regularizing Neural Networks
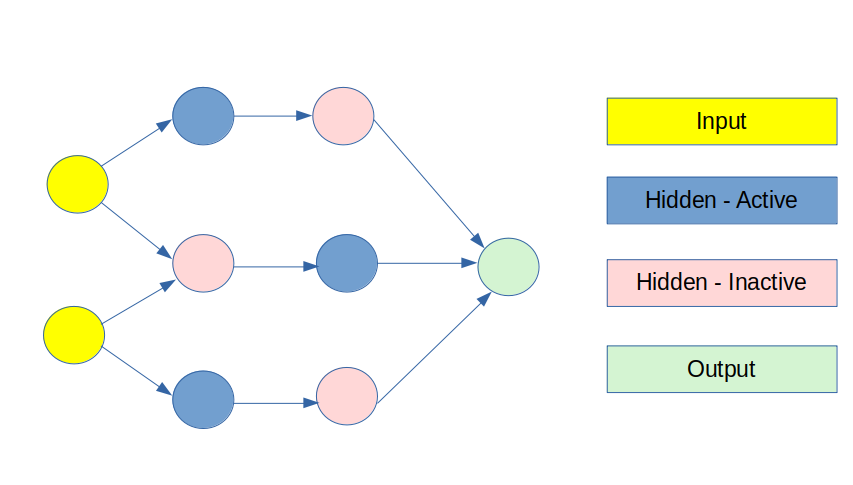
At its most basic, Dropout literally “drops-out” certain neurons from the neural network. This is to prevent excessive “noise” in the network that artificially increases the training accuracy, but does not result in any meaningful information being transferred to the output layer — i.e. any increase in the training accuracy comes from excessive training and not from any useful information from the model features themselves.
Dropout renders certain nodes in the network inactive as illustrated in the image at the beginning of this article — thus forcing the network to look for more meaningful patterns that influence the output layer.
While Dropout can technically be used in both the input and hidden layers — it is most common to use Dropout across the hidden layers, as using it on the input layer still risks discarding important information.
Predicting Average Daily Rates For Hotels: Regression-Based Neural Network
To investigate the effectiveness of Dropout in predicting the output layer, let’s use a regression-based neural network to predict ADR (average daily rates) for customers at a hotel.
The original research by Antonio, Almeida, and Nunes (2016) is available in the References section below.
The following features are used to predict ADR:
- IsCanceled (whether the customer cancels their booking or not)
- Country of Origin
- Market Segment
- Deposit Type
- Customer Type
- Required Car Parking Spaces
- Week of Arrival (Week Number)
Datasets
Let’s consider two training datasets.
Dataset 1 is the original dataset with 40,060 observations. Dataset 2 is a smaller version of the original with 100 observations.
A regression-based neural network model is built on each in order to predict ADR values across the test set (a separate dataset). The datasets and code for this example are available in the references section below.
Neural Networks without Dropout
Dataset 1 — Model Configuration
- 8 input layers are used in the network
- **ELU **is used as the activation function.
- A linear output layer is used.
- 1,669 hidden nodes are used in the hidden layer.
#data-science #machine-learning #regularization #overfitting #neural-networks #neural networks