In this article, I will create a dataset from scratch using Pandas, but referencing the values of other cells while filling the dataset.
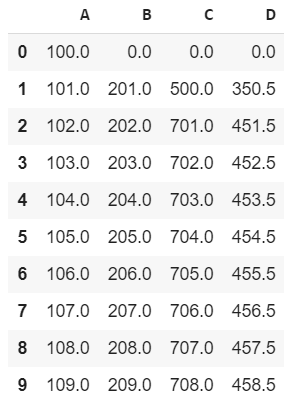
I created this dataset from scratch using Pandas
One of the missing features of Pandas is creating similar functions as Excel. Excel is a great tool when we have to deal with a limited amount of information manually. One of the most intuitive features of this spreadsheet are functions.

how Pandas/Excel mixed Logo may look
In regards to Pandas, one of the most uncomfortable reasons why people struggle to appreciate it from the beginning is that editing data inside the dataset is really challenging. What if I want to create a dataset from scratch and I need to use functions that take info from previous rows and columns?
Excel Version
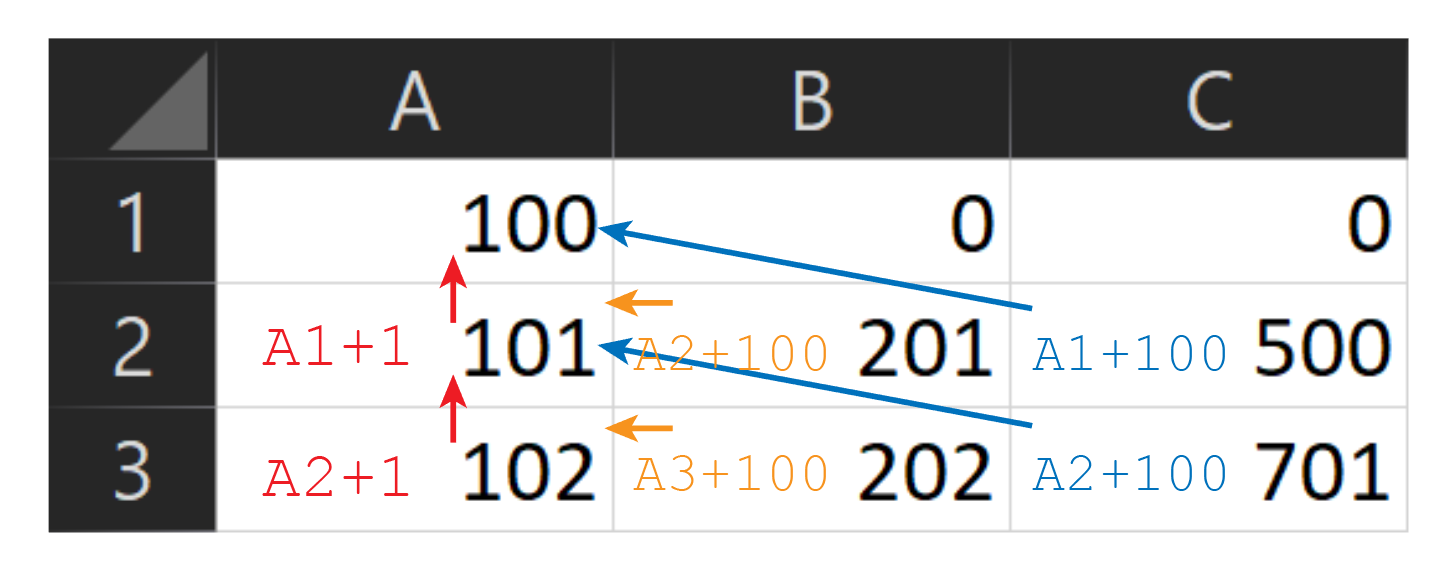
Using Excel Formulas
We obtain the following dataset:
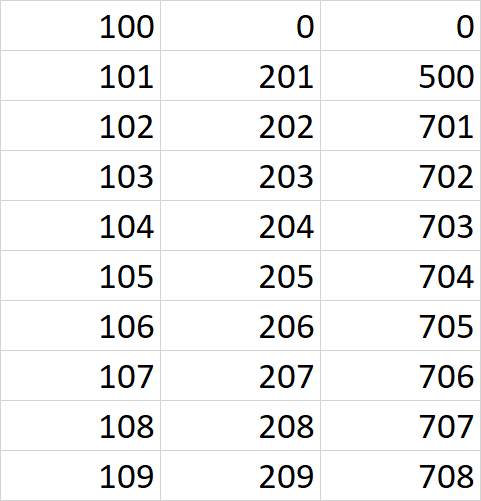
10 rows of the dataset
Pandas Version
We could save this file as a .csv, however, the purpose of this article is to replicate the same procedure with pandas. I am going to create a dataset from scratch using these relative functions.
Creating the first row
I will be using a for the statement to create the rest of the rows. Like in Excel, the first row should not contain any function, but only data. I am just going to create an empty row to set the columns of the dataset.
import pandas as pd
df = [0, 0, 0]
df = pd.DataFrame(df).transpose()
df.columns = ['A', 'B', 'C']
df
empty dataset
Setting values
I could have done this before, but I prefer to proceed one step at a time.
df['A'][0] = 100
d
#coding #algorithms #excel #pandas-dataframe #python #function
