Introduction: [Toy Browser] Introduction
Previous article: [Toy Browser] HTTP Request and Response Parse
**Keywords: **HTML, CSS, DOM Tree, Finite-state machine
In previous article, toy browser can send a request to the server, receive its response, and parse the response. Now, HTML file is extracted. Next step, we need to create a DOM Tree by parsing HTML. It’s the most tricky and interesting part of toy browser. The codes of HTML Parser will help you understand it. In general, the HTML Parser does following things in the order:
- parse HTML character by character
- tokenize HTML tag by tag
- create the nodes of DOM Tree from the tokens, and mount the nodes on the tree
- compute CSS rules and apply them on the nodes of the DOM Tree
HTML Parse
As parsing response and chunked response body, our old friend, Finite-state machine will help us parsing HTML. Different from the previous tasks, HTML is much more complicated. Fortunately, whatwg.org has defined all the states for us (check here, tokenization). Unfortunately, there are 80 states ! To make the toy browser simple, I chose some of the states.
- tagOpen, tagName, endTagOpen
- beforeAttributeName, afterAttributeName, attributeName
- beforeAttributeValue, doubleQuotedAttributeValue, singleQuotedAttributeValue, UnquotedAttributeValue, afterQuotedAttributeValue
- selfClosingStartTag
- data, EOF
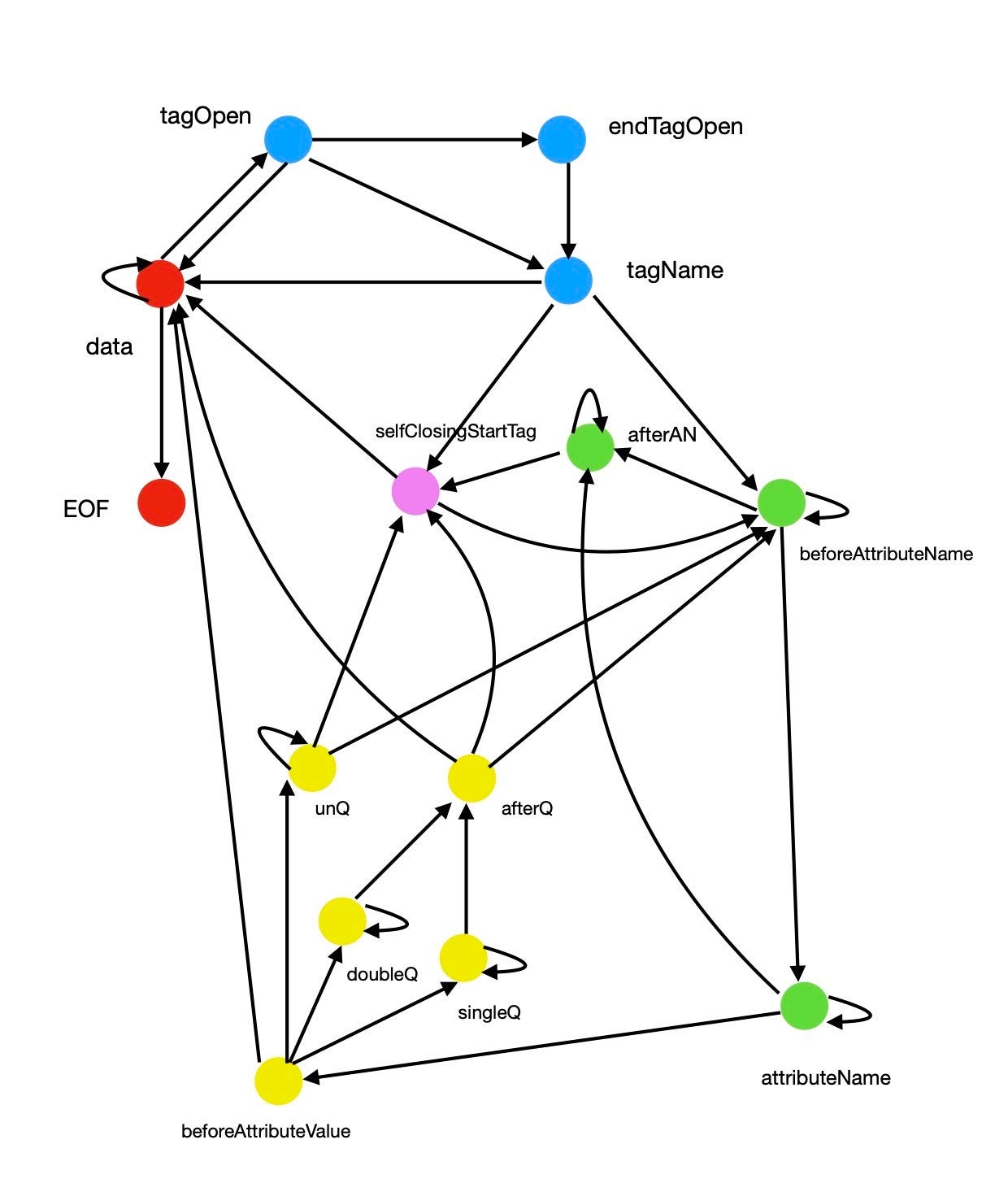
Finite-states machine for parsing HTML of toy browser
#html #html-parsing #css
![[Toy Browser] HTML Parsing and CSS Computing](https://miro.medium.com/max/1200/1*IyraICw9e6Cz1_sQ8piUqA.jpeg)