Novels often offer a complex narrative that can be difficult to follow throughout the book for a reader. Proposing tools that help gain a better comprehension is therefore an interesting path, which is still rather unexplored yet. Indeed, despite the recent development of NLP algorithms like GPT-3 that produce outstanding performances in a wide variety of tasks (translation, question answering, text generation…), getting a true understanding of the book or even a good summary is still out of reach.
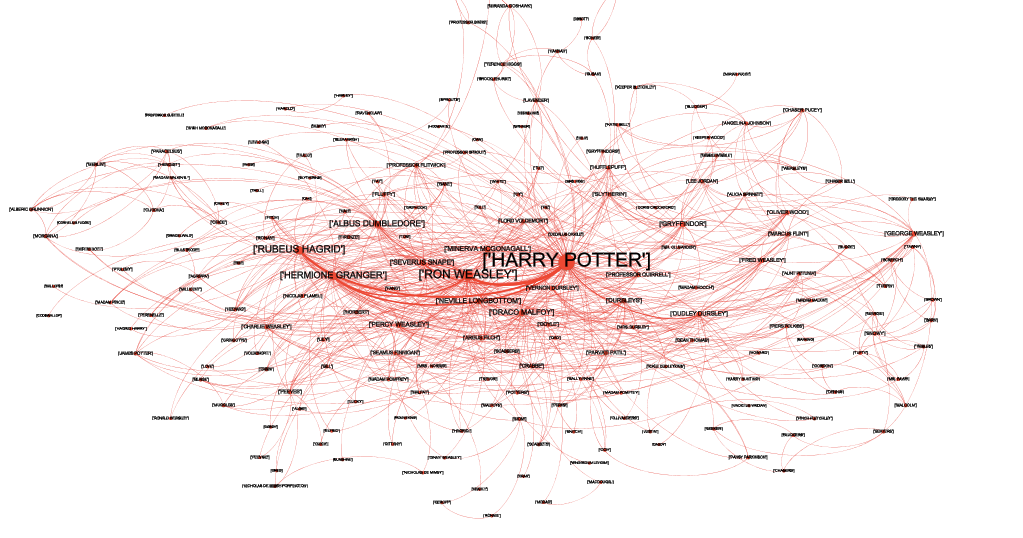
Nevertheless, there exists other ways to get rewarding insights from a novel. In this post, we turn to a concept that is at the crossroad of Natural Language Processing (NLP) and Network Science (NS) — a new and evolving branch of applied graph theory that brings together traditions from many disciplines, including mathematics, sociology, economics and computer science [3]. More precisely, we create a relevant dynamic heterogeneous social network of characters from the book’s textual content, and then leverage information from this graph to improve one’s comprehension of the novel. In particular, we focus on five different applications: characters’ importance, narrative structural change, community detection, summarisation and book comparison. Investigating them gives us precious clues about the book’s plot, the author’s style or characters’ importance, relations and roles.
We apply our analysis to the famous book of J.K. Rowling: “Harry Potter and the Philosopher’s Stone” (HP1) — although the analysis could be applied to absolutely any book.

At this moment you might still be wondering “But w_hat is a dynamic heterogenous social network of characters _?” To answer your question, a network of characters is nothing more than a graph, meaning a set of nodes V and edges E, where nodes represent characters of the book and edges interactions between them. While the vast majority of approaches in the literature focus on static methods, that are by definition fixed in time — one graph for the entire book, we follow a dynamic approach — a graph that constantly evolves in time and enables to keep the narrative’s temporal information. To create this dynamic aspect, we additionally make the graph heterogenous, that is, with several edge types and node types. In other words, all nodes will not be representing characters and all edges will not be representing interactions between them. But we will come back to this later.
Here is a more accurate overview of what will be covered.
- Text processing
- (1) Retrieve the book from the Internet and split it by chapter
- (2) Extract character names that appear in the text
- (3) Match each character occurrence with the corresponding entity
- Graph creation
- (1) Construct the full dynamic heterogenous graph
- (2) Derive from it multiple graphs of interest (dynamic entity graph, static entity graph…)
- (3) Visualisation with a special software called gephi
- **Graph Analysis **— with networkx
- (1) Character importance
- (2) Structural change in the narrative
- (3) Community detection
- (4) Books’ writing style comparisons
- (5) Summarisation of a book via the graph’s k-core
- (6) Other applications: relation prediction, genre/author/style classification…

For more details about the Preprocessing and Graph Creation sections, you can refer to the original paper, where the code is available on Github. But feel free to skip them if the Graph Analysis part is the only thing you are interested in.
Preprocessing
In order to create a sort of dynamic character graph, we first need to do some NLP on the raw text. The pre-processing module aims to capture all occurrences of all characters in the book, under their different forms; and store the following information:
character_name: [str] name of character (eg: ‘Harry’)
pos: [int] number of tokens since beginning (eg: 30490)
chapter: [int] index of the chapter (eg: 2)
entity : [str] corresponding entity (eg: ‘HARRY POTTER’)
- We retrieve the book from the Internet, in .txt format, using Project Gutenberg library and split it by chapter. Why ? Because the chapter is a unit of interest for the plot evolution.
- **We run **BERT NER — the pre-trained google BERT fine tuned for entity recognition tasks — on the whole book, chapter by chapter, to detect all character occurrences. We only keep ‘PER’ entities (persons), which we store together with their position in the text and the corresponding chapter index.
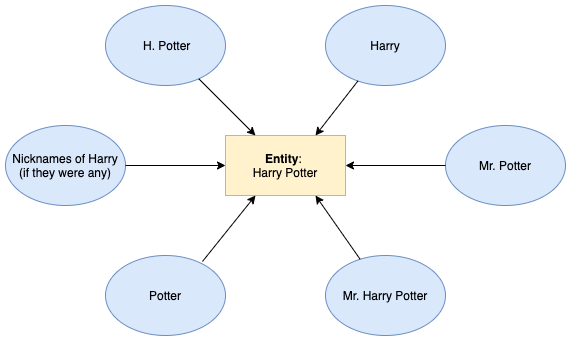
- **We match each character mention to a unique entity **(= protagonist). A social network relates entities, and thus it is a crucial step to group all the co-referents together. For instance, regarding Harry Potter, we would like Harry, Potter, Mr. Potter, H. Potter to be linked to a single entity. In this case HARRY POTTER. We follow the strategy developed by M.Ardanuy and C.Sporleder in [1] for this character resolution task. This is been done in 4 steps:
- Human name parsing: use NameParser framework to parse a character name into a generic structure. For instance, Mr. Harry Potter will be parsed into : {title: Mr, first: Harry, last: Potter}
- Gender assignation. Determine, if possible, the genre of the character. Here we simply assess it from the title and from the first name, using databases. For example, if the title is ’Mr’, the genre is ‘Male’.
- Matching algorithm: maps each occurrence to an entity, grouping co-referents together. Without delving too much into details, let’s say that we first consider all occurrences showing a title, a first name and a last name — occurrences with the most complete form. If no existing entity has the occurrence’s first name, last name and eventually genre, we create a new one. We proceed as such for all mentions showing the same structure, and then focus on remaining ones that display first name and a last name only. Again, we repeat the same process, matching a new mention to an existing entity if first name and last name are the same. Next comes occurrences with title and first name, title and last name and finally first or last name. As a result, since the entity HARRY POTTER is conceived at the very beginning (by Mr. Harry Potter), Harry or Mr. Potter are directly associated to this entity.
- Refined matching process: considers nicknames, initials and small mistakes of the NER model. Indeed, in the current framework, H. Potter and Duddy are distinct entities and are not mapped to Harry Potter and Dudley Dursley, as we would like them to. We solved this issue by specifying carefully targeted rules to deal with initials and by using an existing nicknames database.
#artificial-intelligence #harry-potter #nlp #network-science