A classification tree is very alike to a regression tree, besides that it is
used to predict a qualitative response rather than a quantitative one. classification tree, we predict that each observation belongs to the most ordinarily occurring class of training observations in the region to which it belongs.
In the classification, RSS cannot be used for making the binary splits. An alternative to RSS is the classification error rate. we assign an observation in a given region to the most commonly occurring class of training observations in that region,** the classification error rate is simply the fraction of the training observations in that region that do not belong to the most common class:**
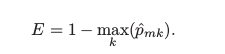
p̂mk = proportion of training observations in the mth region that is from the kth class.
classification error is not good enough for tree-growing, and in practice, two other measures are favoured.
- Gini index is defined by a measure of total variance across the K classes. It takes on a small value if all of the p̂mk ’s are close to 0 or 1. Therefore it is referred to as a **measure of node purity **— a small value shows that a node contains predominantly observations from a single class.
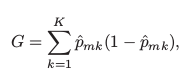
2.** Cross-Entropy **is given by
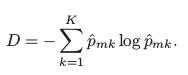
Since, 0 ≤ p̂mk ≤ 1, it follows that 0 ≤ −p̂mk log p̂mk. The cross-entropy will take on a value near zero if the p̂mk ’s are all near 0 or near 1. Therefore, the cross-entropy will take on a small value if the mth node is pure. It turns out that the Gini index and the cross-entropy are quite similar numerically.
Two approaches are more sensitive to node purity than is the classification error rate. Any of these three approaches might be used when pruning the tree, but the classification error rate is preferable if the prediction accuracy of the final pruned tree is the goal.
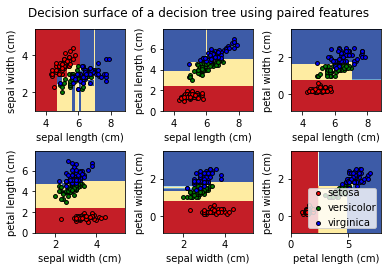
Decision tree classifier using sklearn
To implement the decision tree classifier, we’re going to use scikit-learn, and we’ll import our ‘’DecisionTreeClassifier’’ from sklearn.tree
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
Load the Data
Once the libraries are imported, our next step is to load the data, which is the iris dataset, itis a classic and very easy multi-class classification dataset available in sklearn datasets. This data sets consists of 3 different types of irises’ (Setosa, Versicolour, and Virginica) petal and sepal length, stored in a 150x4 numpy.ndarray. The rows being the samples and the columns being: Sepal Length, Sepal Width, Petal Length and Petal Width.
#iris-dataset #decision-tree #decision-tree-classifier #machine-learning #sklearn #deep learning