According to the ICAO standard, the passport number should be up to 9 characters long and can contain numbers and letters. During your work as an analyst, you can come along a data set containing the passports and you will be asked to explore it.
I have recently worked with one such set and I’d like to share the steps of this analysis with you, including:
- Number of records
- Duplicated records
- Length of the records
- Analysis of the leading and trailing zeros
- Appearance of the character at a specific position
- Where do letters appear in the string using regular expressions (regexes)
- Length on the sequence of letters
- Is there a common prefix
- Anonymize/Randomize the data while keeping the characteristics of the dataset
You can go through the steps with me. Get the (randomized data) from github. It also contains the Jupiter notebook with all the steps.
Basic Dataset Exploration
First, let’s load the data. Since the dataset contains only one column, it’s quite straightforward.
# import the packages which will be used
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv(r"path\data.csv")
df.info()
The .info() command will tell us that we have 10902 passports in the dataset and all are imported as “object” which means that the format is string.
Duplicates
As an initial step of any analysis should be the check if there are some duplicated values. In our case, there are, so we will remove them using pandas’s .drop_duplicates() method.
print(len(df["PassportNumber"].unique()))# if lower than 10902 there are duplicates
df.drop_duplicates(inplace=True) # or df = df.drop_duplicates()
Length of the passports
Usually, you continue with the check of the longest and the shortest passport.
[In]: df["PassportNumber"].agg(["min","max"])
[Out]:
min 000000050
max ZXD244549
Name: PassportNumber, dtype: object
You might become happy, that all the passports are 9 characters long, but you would be misled. The data are having string format so that the lowest “string” value is the one which starts with the highest number of zeros and the largest the one which has the most zeds at the beginning.
# ordering of the strings is not the same as order of numbers
0 > 0001 > 001 > 1 > 123 > AB > Z > Z123 > ZZ123
In order to see the length of the passports let’s look at their length.
[In]: df["PassportNumber"].apply(len).agg(["min","max"])
[Out]:
min 3
max 17
Name: PassportNumber, dtype: object
In the contracts to our initial belief, the shortest passport contains only 3 characters while the longest is 17 (way over the expected maximum of 9) characters long.
Let’s expand our data frame with the 'len'column so that we can have a look at examples:
# Add the 'len' column
df['len'] = df["PassportNumber"].apply(len)
# look on the examples having the maximum lenght
[In]: df[df["len"]==df['len'].max()]
[Out]:
PassportNumber len
25109300000000000 17
27006100000000000 17
# look on the examples having the minimum lenght
[In]: df[df["len"]==df['len'].min()]
[Out]:
PassportNumber len
179 3
917 3
237 3
The 3 digit passport numbers look suspicious, but they meet the ICAO criteria, but the longest ones are obviously too long, however, they contain quite many trailing zeros. Maybe someone just added the zeros in order to meet some data storage requirements.
Let’s have a look at the overall length distribution of our data sample.
# calculate count of appearance of various lengths
counts_by_value = df["len"].value_counts().reset_index()
separator = pd.Series(["|"]*df["len"].value_counts().shape[0])
separator.name = "|"
counts_by_index = df["len"].value_counts().sort_index().reset_index()
lenght_distribution_df = pd.concat([counts_by_value, separator, counts_by_index], axis=1)
# draw the chart
ax = df["len"].value_counts().sort_index().plot(kind="bar")
ax.set_xlabel("position")
ax.set_ylabel("number of records")
for p in ax.patches:
ax.annotate(str(p.get_height()), (p.get_x() * 1.005, p.get_height() * 1.05))
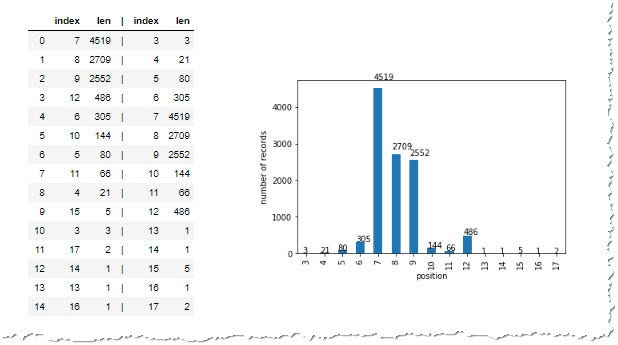
Distribution of the passport lengths of the data sample
We see, that the most passports number in our sample, are 7, 8 or 9 characters long. Quite a few are however 10 or 12 characters long, which is unexpected.
Leading and trailing zeros
Maybe the long passports are having leading or trailing zeros, like our example with 17 characters.
In order to explore these zero-pads let’s add two more columns to our data set — ‘leading_zeros’ and ‘trailing_zeros’ to contain the number of leading and trailing zeros.
# number of leading zeros can be calculated by subtracting the length of the string l-stripped off the leading zeros from the total length of the string
df["leading_zeros"] = df["PassportNumber"].apply(lambda x: len(x) - len(x.lstrip("0")))
# similarly the number of the trailing zeros can be calculated by subtracting the length of the string r-stripped off the leading zeros from the total length of the string
df["trailing_zeros"] = df["PassportNumber"].apply(lambda x: len(x) - len(x.rstrip("0")))
Then we can easily display the passport which has more than 9 characters to check if the have any leading or trailing zeros:
[In]: df[df["len"]>9]
[Out]:
PassportNumber len leading_zeros trailing_zeros
73846290957 11 0 0
N614226700 10 0 2
WC76717593 10 0 0
...
#pandas #exploratory-data-analysis #data-analysis #dataset #data analysis