This article throws light on the performance of Long Short-Term Memory (LSTM) and Transformer networks. We’ll start with taking cognizance of information on LSTM ’s and Transformers and move on to internal mechanisms with which they work. Let’s understand what’s happening under the hood and how Transformers are able to perform exceptionally well compared to LSTM’s.
What is RNN and how does it work?
Before learning about LSTM networks, let’s be aware of how Recurrent Neural Networks (RNN) work. RNN is a type of Neural Network where the output from the previous time step is fed as input to the current time step. Unlike feedforward neural networks, RNNs can use their internal state (memory) to process sequences of inputs. Therefore, neural RNNs are good at modelling sequence data.
In traditional neural networks, all input and output is independent on each other; whereas in cases when it’s required to have sequential information to predict the next word of the sentence, the previous words are required and hence a need to remember the previous words. Thus, RNN came into existence. They solve this issue with the help of a loop structure. The main and most important feature of RNN is the “Hidden” state that remembers information about a sequence. This makes them applicable to tasks such as unsegmented, connected handwriting recognition or speech recognition.
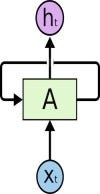
Source: colah’s blog
This loop structure allows the neural network to take the sequence of input. If you see the unrolled version, you will understand it better.
#neural-networks #lstm #transformers #deep-learning #rnn