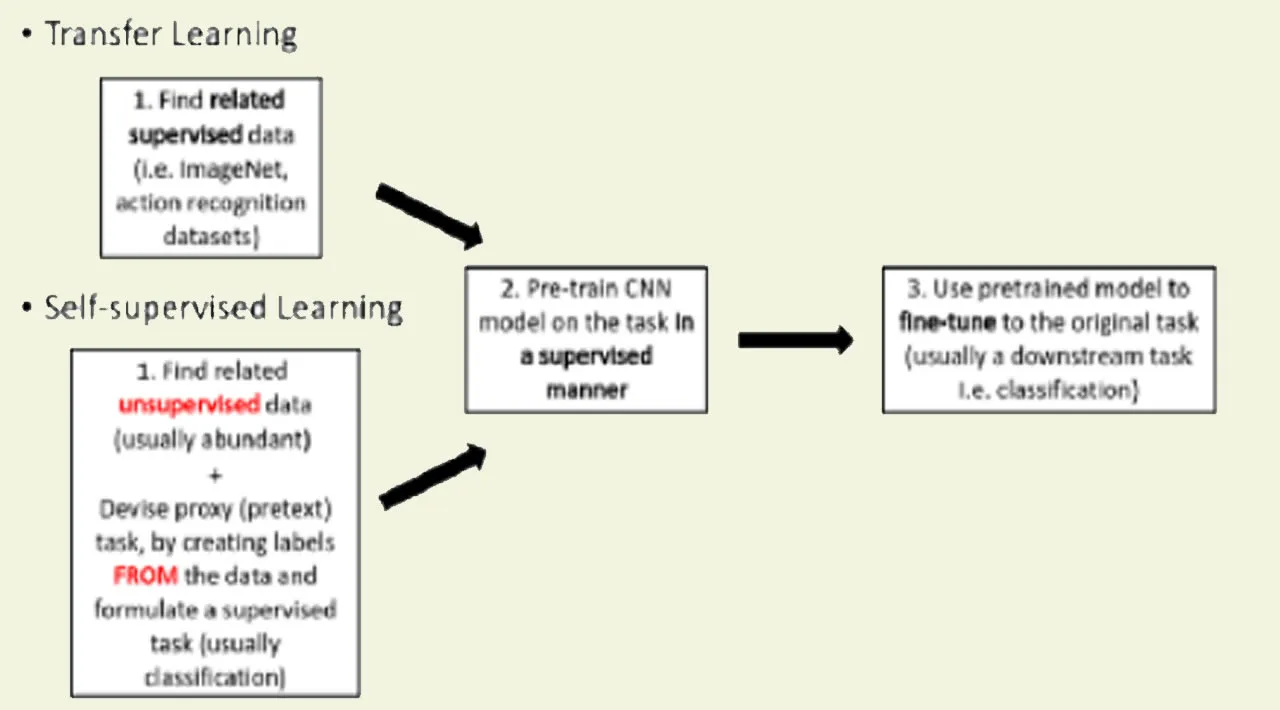
Nowadays, transfer learning from Imagenet is the absolute standard in computer vision. Self-supervised learning dominates natural language processing, but this doesn’t mean that there are no significant use-cases for computer vision that it should be considered.
There are indeed a lot of cool self-supervised tasks that one can devise when one deals with images, such as jigsaw puzzles [6], image colorization, image inpainting, or even unsupervised image synthesis.
But what happens when the time dimension comes into play? How can you approach the video-based tasks that you would like to solve?
So, let’s start from the beginning, one concept at a time. What is self-supervised learning? And how is it different from transfer learning? What is a pretext task?
#self-supervised-learning #video-processing #machine-learning #deep-learning