Let’s learn how to implement ClickModels in order to extract Relevance from clickstream data.

Image by Joshua Golde
Building a search engine system usually follows some well-known steps for the most part:
- Choose an appropriate database for the search operation.
- Save a set of documents.
- Apply transformations to the documents fields (remove accents, filter plural, break white spaces…).
- Create a querying rule for retrieving those documents.
These steps tend to be what is already necessary for implementing an effective enough search engine system for a given application.
Eventually, the requirement to upgrade the system to deliver customized results may arise. Doing so should be simple. One could choose from a set of machine learning ranking algorithms, train some selected models, prepare them for production and observe the results.
It can be that simple indeed except for one missing part: regardless of the chosen ranking model, we still need to somehow prepare a training dataset capable of teaching the algorithms on how to properly rank. There’s got to be, somehow, a dataset telling the algorithms what is a good document versus a bad one.
And that’s going to be the main focus of this post . In order to push search engines to the next level with AI algorithms, a training data that “teaches” algorithms on how to properly rank results is fundamental.
We’ll discuss how to use ClickModels, a field that uses Probabilistic Graphical Models (PGM), to develop a set of variables that explains the interactions between users and the retrieved documents. Those variables will provide us the concept of relevance (or judgment, as also known in the literature) which basically works as a marker of how much valuable a document is for a given search query.
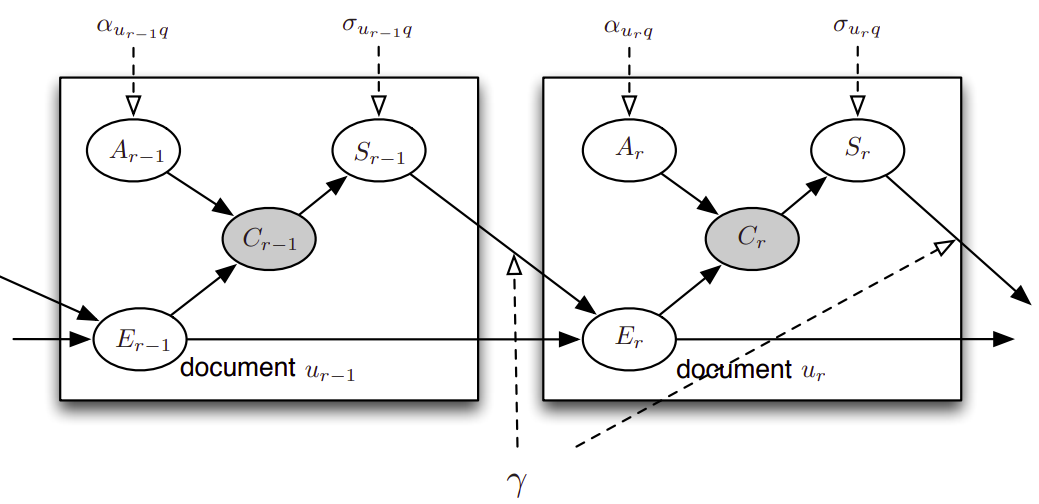
Example of Graphical Model used to infer Relevance from Clickstream data. Image taken from clickmodels book publicly available.
Our challenge will be to create a probabilistic model that learns from users interactions how much relevant documents are for each query and context. Final code built on top of Cython can be found on pyClickModels repository (Cython is required as the optimization process of these algorithms may take a considerable amount of time to converge).
So, with no further ado, let’s see how to take search engines to the next level.
So, Relevance Why?
Figuring out what is relevant for people can be quite challenging. Imagine working on building a search engine for an eCommerce store.
Example of Search Results for search query “smartphone”. Image by author.
In this environment (and we could argue that most retrieval engines works on similar context), observed data contains:
- What users are searching.
- Context of the search (region of the user, demographic data, their preferences and so on).
- Products they are clicking.
- Products they are purchasing after clicking.
We expect that products purchased from a search result page are quite relevant so they should have a good relevance score. But then we realize that there might be products that weren’t shown to the user (for instance, products at page 2 or higher) that they would end up enjoying even more!
Not only that, several patterns tend to be observed when ranking items to users. For instance, the first document on a result page tends to get more clicks than others, not necessarily because it’s an adequate product for the query but rather simply because it’s on the very first position of the catalog (also known as “position bias”).
Well, now things start to get tricky.
One approach for finding what is relevant to people is simply asking them. And, interestingly enough, that’s actually one available solution used by some companies. But the downsides of this approach is that it doesn’t quite scale well and it tends to be less accurate in general.
Another approach, one that we are interested in, infers implicit relevance from ‘clickstream’ data. Clickstream data is basically the recording of the browsing interactions between users and the search engine system itself. Here’s one example:
{"search_query": "brand 1", "sessions": [{"session ID 1": [{"doc": "doc0", "click": 1}, {"doc": "doc1", "click": 0}]}]}
{"search_query": "product 2", "sessions": [{"session ID 1": [{"doc": "doc2", "click": 1}, {"doc": "doc3", "click": 0}]}]}
Example of Clickstream data.
We can use this information in order to model how relevant each document likely is for each query.
#data-science #search-engine-optimizati #cython #python #machine-learning
