DynamoDB is an incredibly powerful NoSQL Platform. Designing for it correctly requires a complete understanding of your business use case and mapping that to the building blocks provided by DynamoDB. NoSQL design requires a different mindset than RDBMS design. For an RDBMS, you can create a normalized data model without thinking about access patterns. You can then extend it later when new questions and query requirements arise.
By contrast, in Amazon DynamoDB, you shouldn’t start designing your schema until you know the questions that it needs to answer. Understanding the business problems and the application use cases up front is absolutely essential. This article provides DynamoDB best practices in a condensed form including schema-design, secondary indexes etc.
DynamoDB
In a NoSQL database such as DynamoDB, data can be queried efficiently in a limited number of ways, outside of which queries can and will be expensive and slow. In DynamoDB, you design your schema specifically to make the most common and important queries as fast and as inexpensive as possible.
As opposed to a table in a relational database management system (RDBMS), in which the schema is uniform, a table in DynamoDB can hold many different types of data items at one time. In addition, the same attribute in different items can contain entirely different types of information.
NoSQL Design
- In DynamoDB, you design your schema specifically to make the most common and important queries as fast and as inexpensive as possible. Your data structures are tailored to the specific requirements of your business use cases.
- You should maintain as few tables as possible in a DynamoDB application.
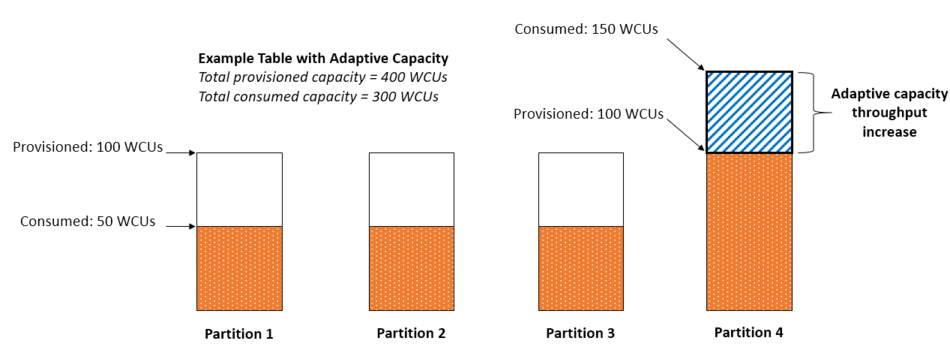
- DynamoDB scales by increasing the number of physical partitions that are available to process queries, and by efficiently distributing data across those partitions. Knowing in advance what the peak query loads might help determine how to partition data to best use I/O capacity.
- Keep related data together. Use sort order. Distribute queries. Use global secondary indexes (enable different queries than your main table can support).
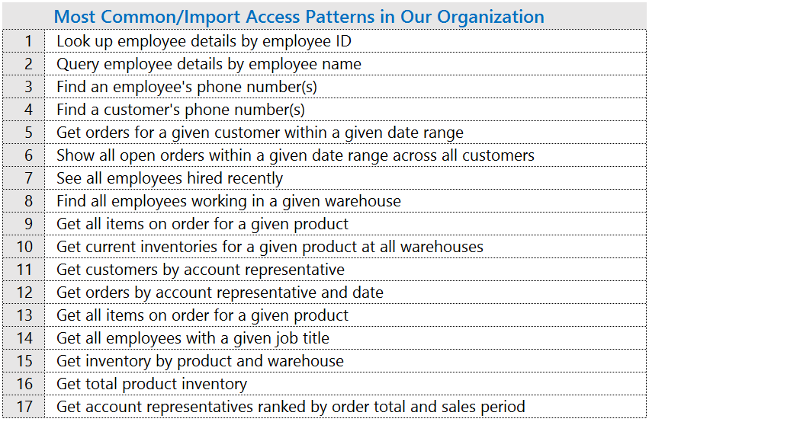
- Take steps to identify the access patterns that are required by the business case. Document the various use cases you identify similar to the following:
Partition-key design
You will use your provisioned throughput more efficiently as the ratio of partition key values accessed to the total number of partition key values increases.
A partition key design that doesn’t distribute I/O requests evenly can create “hot” partitions that result in throttling and use your provisioned I/O capacity inefficiently. You should structure the primary key elements to avoid one “hot” (heavily requested) partition key value that slows overall performance. You can use write sharding to distribute the workloads evenly, for e.g., you can add a random number to the partition key values to distribute the items among partitions. Or you can use a number that is calculated based on something that you’re querying on.
Determine the access patterns that your application requires, and estimate the total read capacity units (RCU) and write capacity units (WCU) that each table and secondary index requires.
Sort key
Sort keys are useful for the following:
- They gather related information together in one place where it can be queried efficiently. Careful design of the sort key lets you retrieve commonly needed groups of related items using range queries with operators such as
begins_with,between,>,<, and so on. - Composite sort keys let you define hierarchical (one-to-many) relationships in your data that you can query at any level of the hierarchy. For example, in a table listing geographical locations, you might structure the sort key as follows. This would let you make efficient range queries for a list of locations at any one of these levels of aggregation, from
country, to aneighborhood, and everything in between.

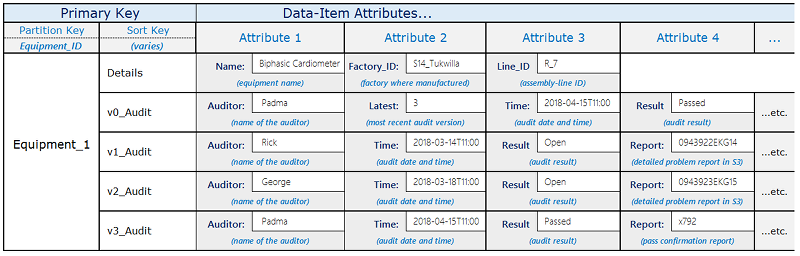
- Version control — For each new item, create two copies of the item: One copy should have a version-number prefix of zero (such as
v0_) at the beginning of the sort key, and one should have a version-number prefix of one (such asv1_). Every time the item is updated, use the next higher version-prefix in the sort key of the updated version, and copy the updated contents into the item with version-prefix zero. This means that the latest version of any item can be located easily using the zero prefix.
#database #dynamodb #aws #nosql #nosql-database