what was before the pre Transformers era
Recurrent neural network (RNN)
A basic Seq2seq model consists of an encoder and decoder. The model takes input sentence with T tokens into the encoder and encodes information one word at a time and outputs a hidden state at every step that stores the sentence context till that point and passed on for encoding the next word. So the final hidden state (E[T]) at the end of the sentence stores the context of the entire sentence.
This final hidden state becomes the input for a decoder that produces translated sentence word by word. At each step, the decoder outputs a word and a hidden state(D[t]) which will be used for generating the next word.
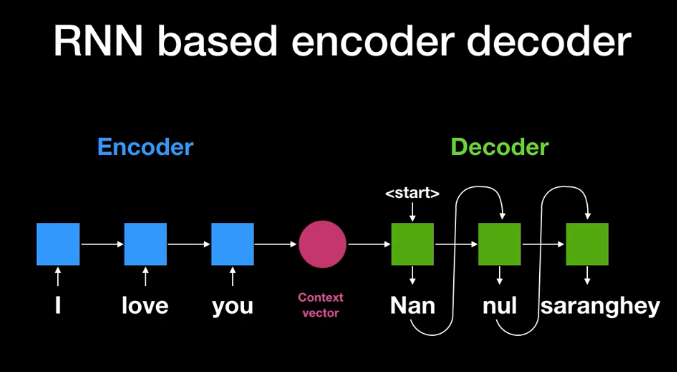
RNN workflow English to Koren
But RNN suffers from the problem of vanishing gradients, making it ineffective for learning the context for long sequences.
RNN based translation with Attention
RNN model with Attention differs in the following things:
- Instead of the last hidden state, all the states (E[0], E[1]…, E[T]) at every step along with the final context vector (E[T]) are passed into the decoder. The idea here is each hidden state is majorly associated with a certain word in the input sentence. using all the hidden state gives a better translation.
- At every time step in the Decoding phase, scores are computed for every hidden state (E[t]) that stores how relevant is a particular hidden state in predicting a word at the current step(t). In this way, more importance is given to the hidden state that is relevant in predicting the current word.
ex: when predicting the 5th word more importance must be given to the 4th, 5th, or 6th input hidden states (depends on the language structure to be translated).
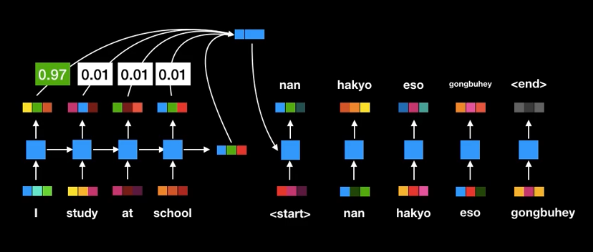
RNN with Attention
This method is a significant improvement over traditional RNN. But RNN lacks a parallelization capability (RNN have wait till the completion of t-1 steps to process at ‘t’th step) which makes it computationally inefficient especially when dealing with a huge corpus of text.
Since RNN’s nature does not allow for parallelization, it possible to drop the RNN and switch to more advanced architecture. And the answer is the Transformer.
Transformer Theory
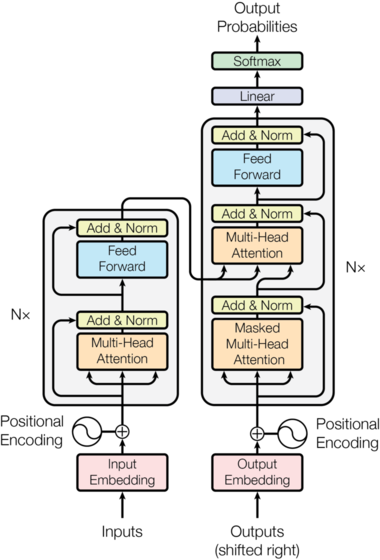
Transformer architecture
The architecture looks complicated, but do not worry because it’s not. It is just different from the previous ones. It can be parallelized, unlike Attention And/or RNN as it doesn’t wait till all previous words are processed or encoded in the context vector.
Positional Encoding
The Transformer architecture does not process data sequentially. So, This layer is used to incorporate relative position information of words in the sentence. Each position has a unique positional vector which is predetermined not learned.
#ai #transformers #deep-learning #translation #nlp #deep learning