Tuning machine learning hyper-parameters is a tedious task we tend to postpone to the very last of the project. Hyper-parameters are everywhere are manual tuning is nearly impossible.
Imagine we have only one hyper-parameter and we want to optimize it. We would have to execute the program, script, algorithm or whatever we are tuning, N times, being N the number of possible values of the parameter. With two parameters, we would have to execute N times for each time of the second parameter, thus, N**2. And so on.
There exist lot of possibilities for hyper-parameter tuning. In this case I will explain an approach from the evolutionary algorithms. Particularly, the _Estimation of Distribution Algorithms (EDAs). _Similar to the Genetic Algorithms. The kernel of this algorithm is that iteratively, the algorithm propose some solutions from which, select the best ones that fit the cost function we want to optimize. From these selection we generate new solutions based on the normal distribution built from them. Figure 1 shows a flow diagram. In each iteration a generation with a group of solutions is sampled. This is called a generation with multiple individuals. In the selection of the best individuals, a percentage of this generation is selected (ALPHA parameter)
This type of algorithm can be used for further tasks as Feature Selection (FS) or optimization of some variables depending on some further fixed values of other variables. Future stories will talk about this topics.
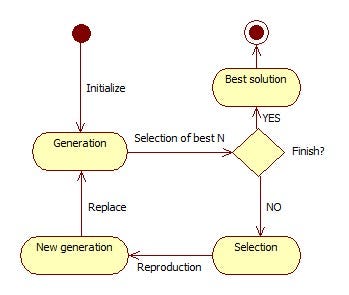
Figure 1. Flow diagram of an Estimation of Distribution Algorithm (EDA).
Lets see an easy example solved using the Python package EDAspy. To install the package just do:
pip install EDAspy
We have a cost function as follows. The three hyper-parameters we want to optimize are dictionary[‘param1’], dictionary[‘param2’] and dictionary[‘param3’]. Also the cost function incorporates some weights. The algorithm must find the optimum values to the hyper-parameters in order to minimize the cost function.
weights = [20,10,-4]
def cost_function(dictionary):
function = weights[0]*dictionary['param1']**2 + weights[1]*(np.pi/dictionary['param2']) - 2 - weights[2]*dictionary['param3']
if function < 0:
return 9999999
return function
The algorithm needs as an input an initial range in which start to evaluate the solutions. Optionally, the algorithm can set a maximum and a minimum for the hyper-parameters. They are all set in a pandas table with a row for each data and a column for each hyper-parameter name. If max and min are not set, do not introduce the max and min rows.
from EDAspy.optimization.univariate import EDA_continuous as EDAc
import pandas as pd
import numpy as np
wheights = [20,10,-4]
def cost_function(dictionary):
function = wheights[0]*dictionary['param1']**2 + wheights[1]*(np.pi/dictionary['param2']) - 2 - wheights[2]*dictionary['param3']
if function < 0:
return 9999999
return function
vector = pd.DataFrame(columns=['param1', 'param2', 'param3'])
vector['data'] = ['mu', 'std', 'min', 'max']
vector = vector.set_index('data')
vector.loc['mu'] = [5, 8, 1]
vector.loc['std'] = 20
vector.loc['min'] = 0
vector.loc['max'] = 100
EDA = EDAc(SIZE_GEN=40, MAX_ITER=200, DEAD_ITER=20, ALPHA=0.7, vector=vector, aim='minimize', cost_function=cost_function)
bestcost, params, history = EDA.run()
print(bestcost)
print(params)
print(history)
#machine-learning #optimization #algorithms
