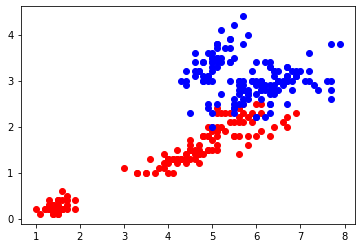
Machine Learning is all about identifying patterns, creating its own algorithm, and consistently evolving. Patterns are usually created by the machine and it uses various techniques and algorithms for it. K nearest neighbor is one the simplest and yet effective algorithm for a classification problem in machine learning. It can be used for both classification and regression problems i.e. it can classify any particular event/attribute and can even predict its value. This method is followed because of its simplicity over other complex algorithms. It works on measuring the distance between the data points. Measuring the distance makes a pattern to create a relationship between two points. This is how it decides in which group the new data point should be placed.
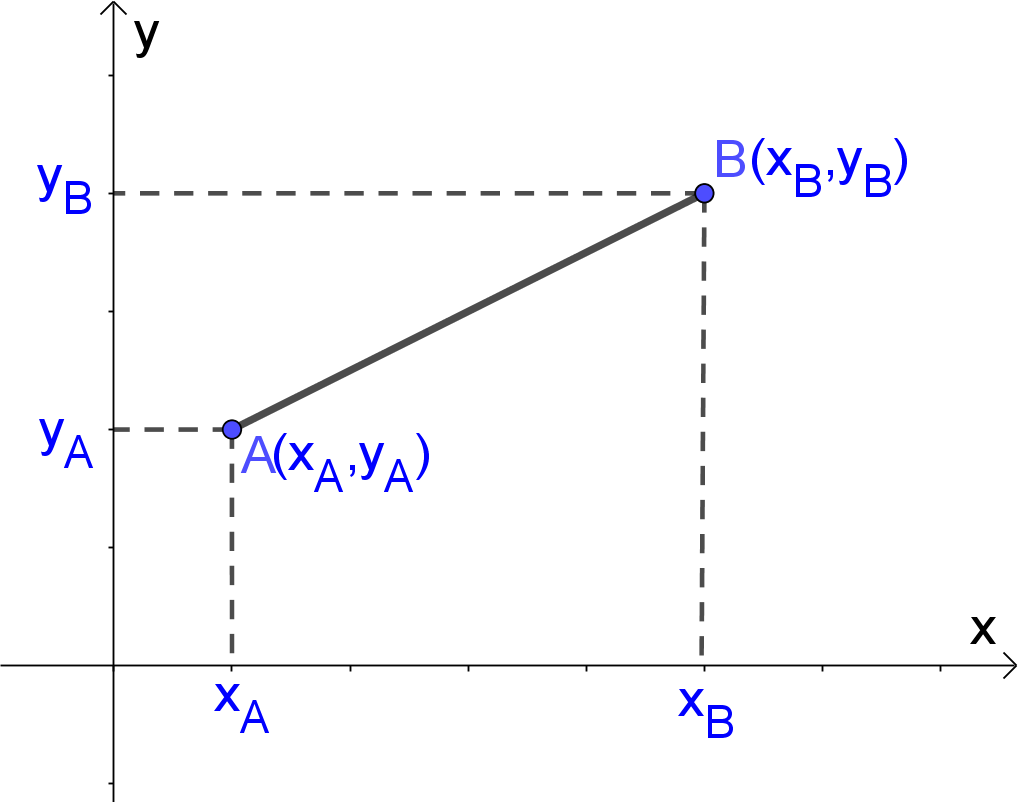
Image taken from nccalculators.com
If we need to calculate the distance between two points mentioned in the above image say (XA,YA)and (XB,YB) then it can be done by using a simple formula
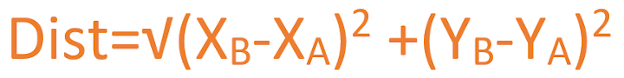
Above is the Euclidean way of measuring the distance between two points. There can be other ways too for this distance measurement. The above mentioned method is followed to calculate the distance between various data points. KNN has two distinct properties
- **Lazy Learning algorithm: **It is called a lazy learner as it does not have any specialized training phase while learning means it has no pre-defined rules. It simply consumes all the data while classifying a new data point and make its own rules.
- Non-parametric learning algorithm: It works on a non-parametric approach means it doesn’t make any assumptions. It doesn’t worry about which features to be selected. Such an approach is quite good for the cases when you have no prior knowledge about incoming data.
#knn #machine-learning-python #data-science #machine-learning