A handbook for learning NLP with basics ideas
Topics to be covered:
Section 1: NLP Introduction, Installation guide of Spacy and NLTK
Section 2: Basic ideas about a text, Regular expression
Section 3: Tokenization and Stemming
Section 4: Lemmatisation and Stop words
Section 5: Part of Speech (POS) and Named Entity Recognition (NER)
Let’s talk about one by one step about these.
Section 1:
Introduction about NLP
Natural Language processing comes under the umbrella of the Artificial Intelligence domain. All computers are good with numerical data to do processing, this class of section is dealing with text data to analyze different languages in this world.
In this article, we will do a morphological study in language processing with python using libraries like Spacy and NLTK.
If we consider raw text data, the human eye can analyze some points. But if we try to build a mechanism in programming using Python to analyze and extract maximum information from the text data.
Let’s consider we will use a jupyter notebook for all our processing and analyzing language processing. Jupyter comes in anaconda distribution.
Installation guide
First, do install anaconda distribution from this link. After installation, anaconda installs Spacy and NLTK library in your environment.
To install the Spacy link is here.
To install the NLTK link is here.
To download the English language library for spacy is
python -m spacy download en #en stands for english
Section 2:
Basic Concept
We all know that the data is the same in both the files. We will learn how to read these files using python because to work on language processing. We need some text data.
Starts with basic strings with variables. Let’s see how to print a normal string.
print('Amit')
#output: Amit
Take an example:
The name of the string is GURUGRAM, the name of my city. When we need to select a specific range of alphabet, then we use the slicing method and indexing method. When we go from left to right, the indexing starts from 0, and when we want the alphabet from right to left, then it starts from minus (-1), not from zero.
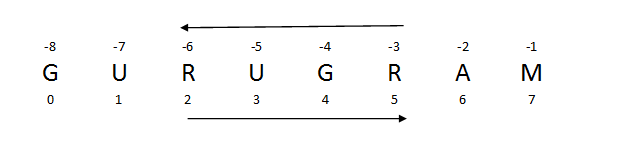
Photo created by the author
With python
#first insert the string to a variable
string = GURUGRAM
#get first alphabet with index
print(string[0])
#output: G
#printing multiple alphabets
print(string[2], string[5])
#output: RR
#for getting alphabet with negative indexing
print(string[-4])
#output: G
Now get the character with slicing
print(string[0:2])
#output: GU
print(string[1:4])
#output: URU
Let’s do some basic with sentences. An example of cleaning a sentence with having starred in it. Lets
I came across a function named is strip() function. This function removes character in the starting and from the end, but it cannot remove character in the middle. If we don’t specify a removing character, then it will remove spaces by default.
#A sentence and the removing character from the sentence
sentence = "****Hello World! I am Amit Chauhan****"
removing_character = "*"
#using strip function to remove star(*)
sentence.strip(removing_character)
#output: 'Hello World! I am Amit Chauhan'
We see the output of the above, and the star is removed from the sentence. So, it’s a basic thing to remove character but not reliable for accuracy.
Like strip function, I also came across a different operation is join operation.
Example:
str1 = "Happy"
str2 = "Home"
" Good ".join([str1, str2])
#output: 'Happy Good Home'
Regular Expression
A regular expression is sometimes called relational expression or RegEx, which is used for character or string matching and, in many cases, find and replace the characters or strings.
Let’s see how to work on string and pattern in the regular expression. First, we will see how to import regular expression in practical.
## to use a regular expression, we need to import re
import re
How to use “re” for simple string
Example:
Let’s have a sentence in which we have to find the string and some operations on the string.
sentence = "My computer gives a very good performance in a very short time."
string = "very"
How to search a string in a sentence
str_match = re.search(string, sentence)
str_match
#output:
<re.Match object; span=(20, 24), match='very'>
We can do some operations on this string also. To check all operations, write str_match. Then press the tab. It will show all operations.
All operations on a string. Photo by author
str_match.span()
#output:
(20, 24)
The is showing the span of the first string “very” here, 20 means it starts from the 20th index and finishes at the 24th index in the sentence. What if we want to find a word which comes multiple times, for that we use the findall operation.
find_all = re.findall("very", sentence)
find_all
#output:
['very', 'very']
The above operation just finds the prints a string that occurs multiple times in a string. But if we want to know the span of the words in a sentence so that we can get an idea of the placement of the word for that, we use an iteration method finditer operation.
for word in re.finditer("very", sentence):
print(word.span())
#output:
(20, 24)
(47, 51)
Some of the regular expressions are (a-z), (A-Z), (0–9), (- .), (@, #, $, %). These expressions are used to find patterns in text and, if necessary, to remove for clean data. With patterns when we can use quantifiers to know how many expressions we expect.
#data-science #nlp #python #programming #machine-learning