During our school days, most of us would have encountered the reading comprehension section of our English paper. We would be given a paragraph or Essay based on which we need to answer several questions.
How do we as humans approach this task at hand? We go through the entire text, make sense of the context in which the question is asked and then we write answers. Is there a way we can use AI and deep learning techniques to mimic this behavior of us?
Automatic text summarization is a common problem in machine learning and natural language processing (NLP). There are two approaches to this problem.
- Extractive Summarization- Extractive text summarization done by picking up the most important sentences from the original text in the way that forms the final summary. We do some kind of extractive text summarization to solve our simple reading comprehension exercises. TextRank is a very popular extractive and unsupervised text summarization technique.
2. Abstractive Summarization-Abstractive text summarization**,** on the other hand, is a technique in which the summary is generated by generating novel sentences by either rephrasing or using the new words, instead of simply extracting the important sentences. For example, some questions in the reading comprehension might not be straightforward in such cases we do rephrasing or use new words to answer such questions.
We humans can easily do both kinds of text summarization. In this blog let us see how to implement abstractive text summarization using deep learning techniques.
Problem Statement
Given a news article text, we are going to summarize it and generate appropriate headlines.
Whenever any media account shares a news story on Twitter or in any social networking site, they provide a crisp headlines /clickbait to make users click the link and read the article.
Often media houses provide sensational headlines that serve as a clickbait. This is a technique often employed to increase clicks to their site.
Our problem statement is to generate headlines given article text. For this we are using the news_summary dataset. You can download the dataset [here]

A tweet from CNN with a headline for an article on COVID 19
Before we go through the code, let us learn some concepts needed for building an abstractive text summarizer.
Sequence to Sequence Model
Techniques like multi-layer perceptron(MLP) work well your input data is vector and convolutional neural networks(CNN) works very well if your input data is an image.
What if my input x is a sequence? What if x is a sequence of words. In most languages sequence of words matters a lot. We need to somehow preserve the sequence of words.
The core idea here is if output depends on a sequence of inputs then we need to build a new type of neural network which gives importance to sequence information, which somehow retains and leverages the sequence information.

Google Translate is a very good example of a seq2seq model application
We can build a Seq2Seq model on any problem which involves sequential information. In our case, our objective is to build a text summarizer where the input is a long sequence of words(in a text body), and the output is a summary (which is a sequence as well). So, we can model this as a Many-to-Many Seq2Seq problem.
A many to many seq2seq model has two building blocks- **Encoder **and **Decoder. **The Encoder-Decoder architecture is mainly used to solve the sequence-to-sequence (Seq2Seq) problems where the input and output sequences are of different lengths.
Generally, variants of Recurrent Neural Networks (RNNs), i.e. Gated Recurrent Neural Network (GRU) or Long Short Term Memory (LSTM), are preferred as the encoder and decoder components. This is because they are capable of capturing long term dependencies by overcoming the problem of vanishing gradient.
Encoder-Decoder Architecture
Let us see a high-level overview of Encoder-Decoder architecture and then see its detailed working in the training and inference phase.
Intuitively this is what happens in our encoder-decoder network:
1. We feed in our input (in our case text from news articles) to the Encoder unit. Encoder reads the input sequence and summarizes the information in something called the internal state vectors (in case of LSTM these are called the hidden state and cell state vectors).
2. The encoder generates something called the context vector, which gets passed to the decoder unit as input. The outputs generated by the encoder are discarded and only the context vector is passed over to the decoder.
3. The decoder unit generates an output sequence based on the context vector.
We can set up the Encoder-Decoder in 2 phases:
- Training phase
- Inference phase
Training phase
A.Encoder
In the training phase at every time step, we feed in words from a sentence one by one in sequence to the encoder. For example, if there is a sentence “I am a good boy”, then at time step t=1, the word I is fed, then at time step t=2, the word am is fed, and so on.
Say for example we have a sequence x comprising of words x1,x2,x3,x4 then the encoder in training phase looks like below:
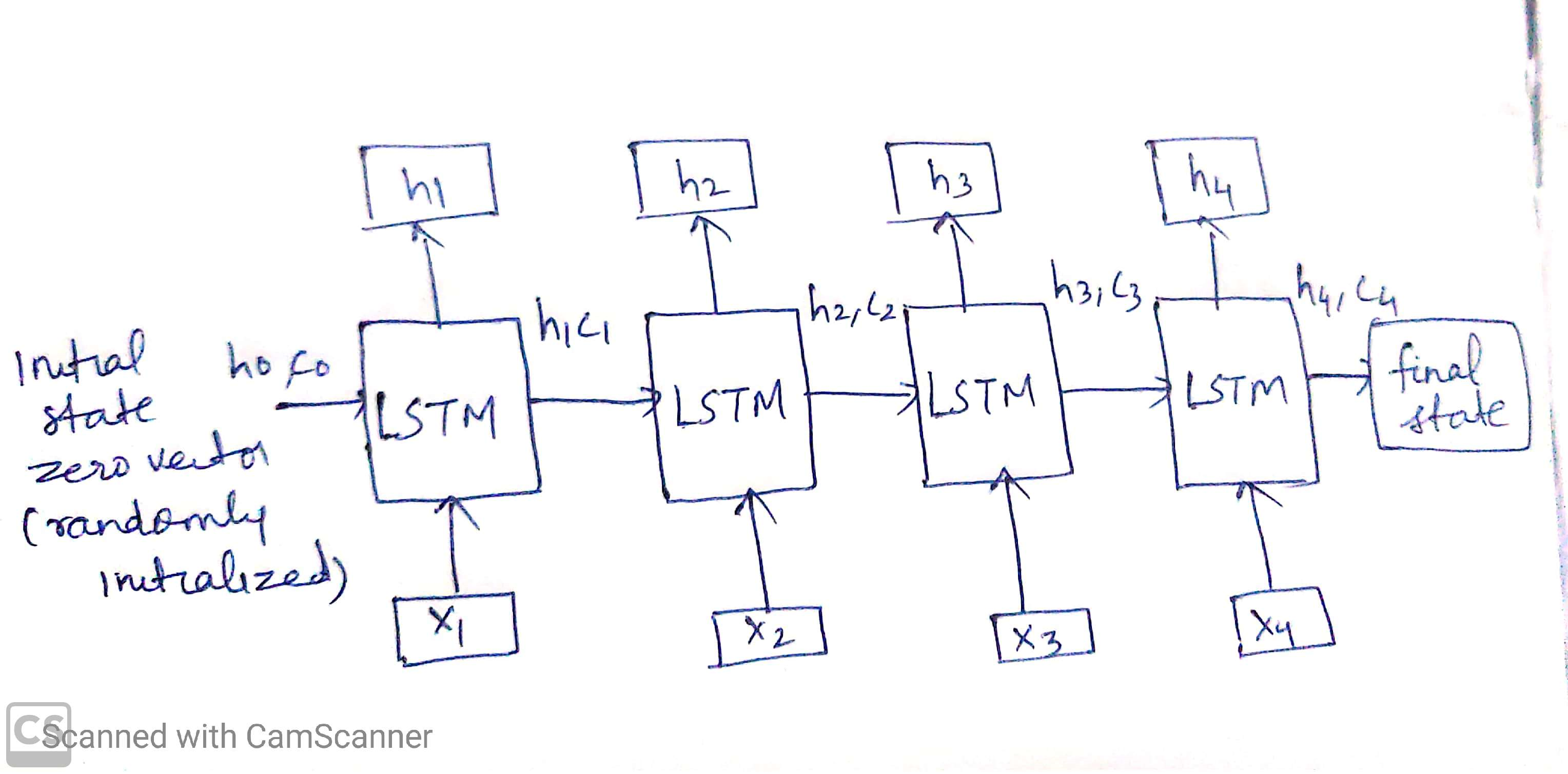
Training Phase
The initial state of the LSTM unit is zero vector or it is randomly initiated. Now h1,c1 is the state of LSTM unit at time step t=1 when the word x1 of the sequence x is fed as input.
Similarly h2,c2 is the state of the LSTM unit at time step t=2 when the word x2 of the sequence x is fed as input and so on.
The hidden state (hi) and cell state (ci) of the last time step are used to initialize the decoder.
#text-summarization #tensorflow #encoder-decoder #deep-learning #deep learning