The Boosting Algorithm is one of the most powerful learning ideas introduced in the last twenty years. Gradient Boosting is an supervised machine learning algorithm used for classification and regression problems. It is an ensemble technique which uses multiple weak learners to produce a strong model for regression and classification.
Intuition
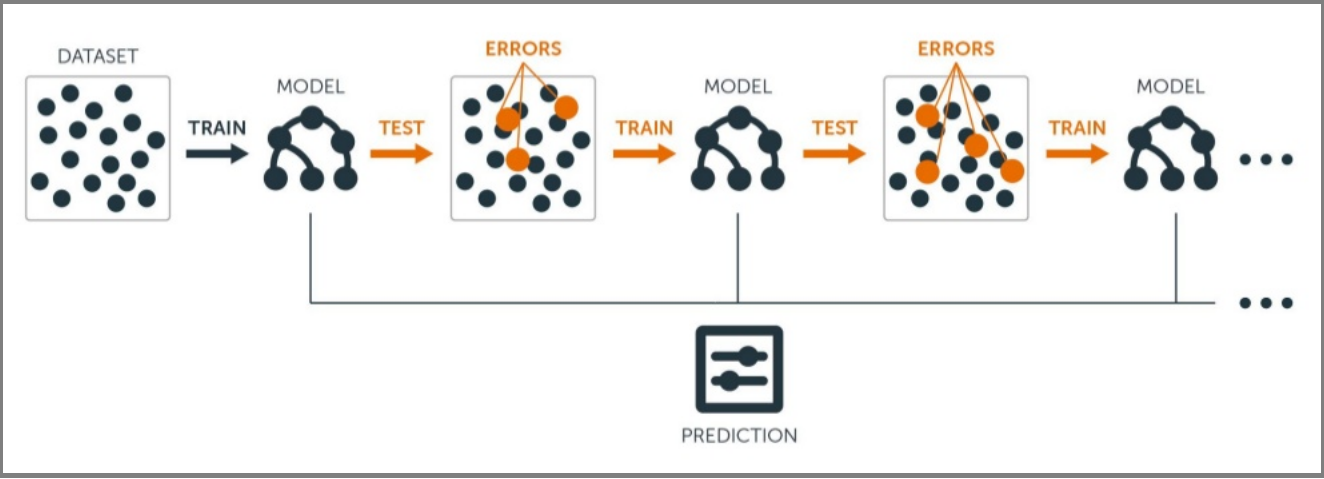
Gradient Boosting relies on the intuition that the best possible next model , when combined with the previous models, minimizes the overall prediction errors. The key idea is to set the target outcomes from the previous models to the next model in order to minimize the errors. This is another boosting algorithm(few others are Adaboost, XGBoost etc.).
Input requirement for Gradient Boosting:
- A Loss Function to optimize.
- A weak learner to make prediction(Generally Decision tree).
- An additive model to add weak learners to minimize the loss function.
1. Loss Function
The loss function basically tells how my algorithm, models the data set.In simple terms it is difference between actual values and predicted values.
Regression Loss functions:
- L1 loss or Mean Absolute Errors (MAE)
- L2 Loss or Mean Square Error(MSE)
- Quadratic Loss
Binary Classification Loss Functions:
- Binary Cross Entropy Loss
- Hinge Loss
A gradient descent procedure is used to minimize the loss when adding trees.
2. Weak Learner
Weak learners are the models which is used sequentially to reduce the error generated from the previous models and to return a strong model on the end.
Decision trees are used as weak learner in gradient boosting algorithm.
3. Additive Model
In gradient boosting, decision trees are added one at a time (in sequence), and existing trees in the model are not changed.
Understanding Gradient Boosting Step by Step :
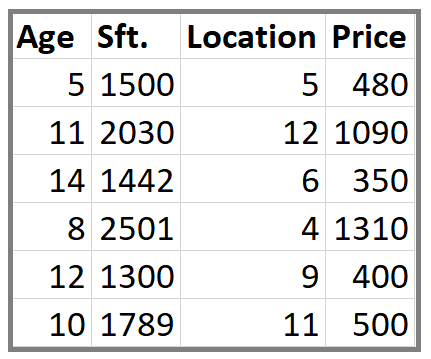
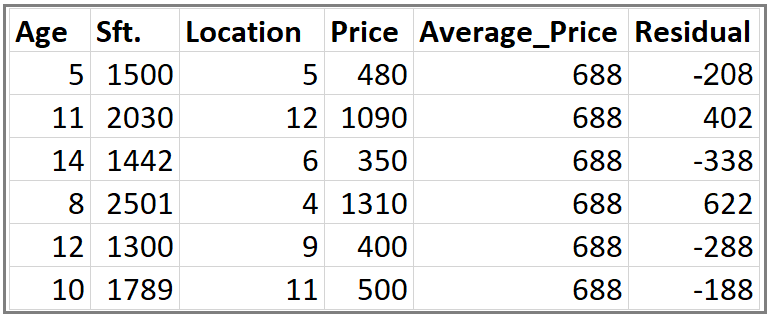
This is our data set. Here Age, Sft., Location is independent variables and Price is dependent variable or Target variable.
Step 1: Calculate the average/mean of the target variable.
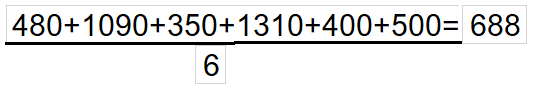
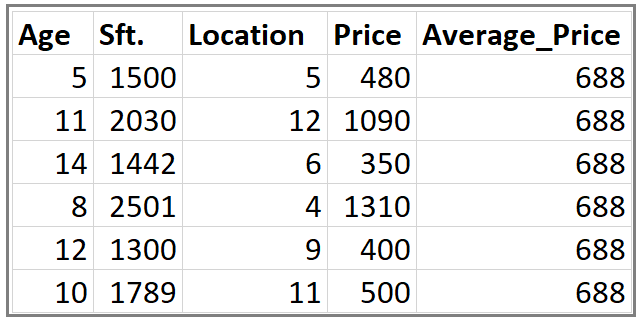
Step 2: Calculate the residuals for each sample.

**Step 3: **Construct a decision tree. We build a tree with the goal of predicting the Residuals.
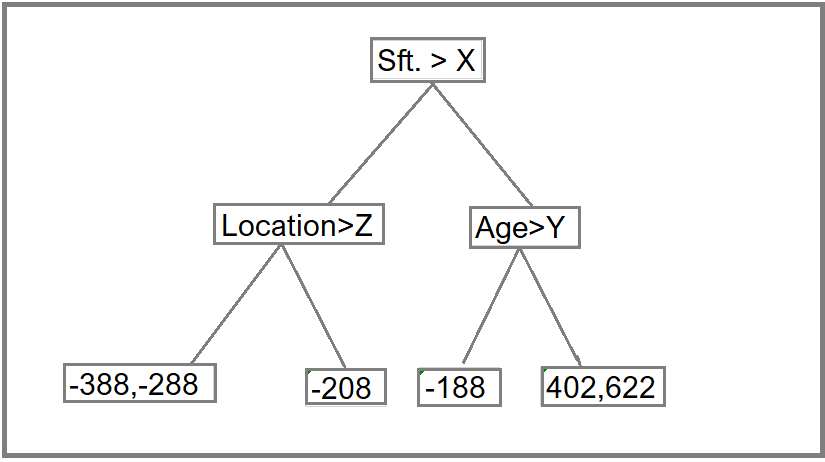
In the event if there are more residuals then leaf nodes(here its 6 residuals),some residuals will end up inside the same leaf. When this happens, we compute their average and place that inside the leaf.


After this tree become like this.
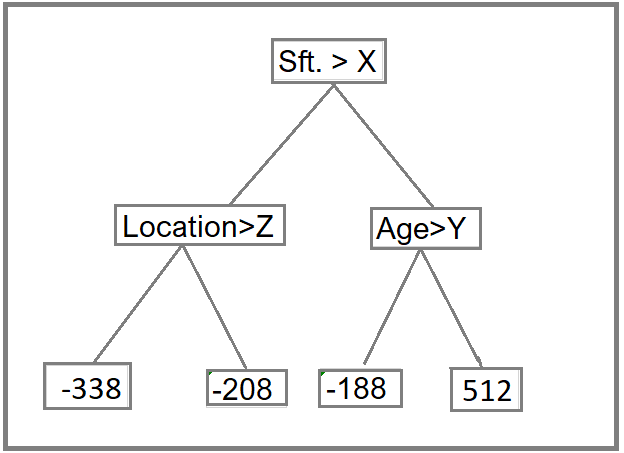
Step 4: Predict the target label using all the trees within the ensemble.
Each sample passes through the decision nodes of the newly formed tree until it reaches a given lead. The residual in the said leaf is used to predict the house price.





Calculation above for Residual value (-338) and (-208) in Step 2
Same way we will calculate the Predicted Price for other values
Note: We have initially taken 0.1 as learning rate.
Step 5 : Compute the new residuals



When Price is 350 and 480 Respectively.
#gradient-boosting #data-science #boosting #algorithms #algorithms
