Get a sense of how to deal with context-specific data structures with pdfminer, numpy and pandas
What is semi-structured data?
In today’s work environment PDF documents are widely used for exchanging business information, internally as well as with trading partners. Naturally, you’ve seen quite a lot of PDFs in the form of invoices, purchase orders, shipping notes, price-lists etc. Despite serving as a digital replacement of paper PDF documents present a challenge for automated manipulation with data they store. It is as accessible as data written on a piece of paper since some PDFs are designed to transfer information to us, humans, but not computers. Such PDFs can contain unstructured information that does not have a pre-defined data model or is not organized in a pre-defined manner. They are typically text-heavy and may contain a mix of figures, dates and numbers.
With the majority of available tools very often you have to process the entire PDF document, having no option to limit the data extraction to a specific section where the most valuable data lies in. However, some PDF table extraction tools do just that. Sad to say that even if you are lucky enough to have a table structure in your PDF it doesn’t mean that you will be able to seamlessly extract data from it.
For example, let’s take a look at the following text-based PDF with some fake content. It has quite noticeable and distinguishing (although borderless) rows and columns:
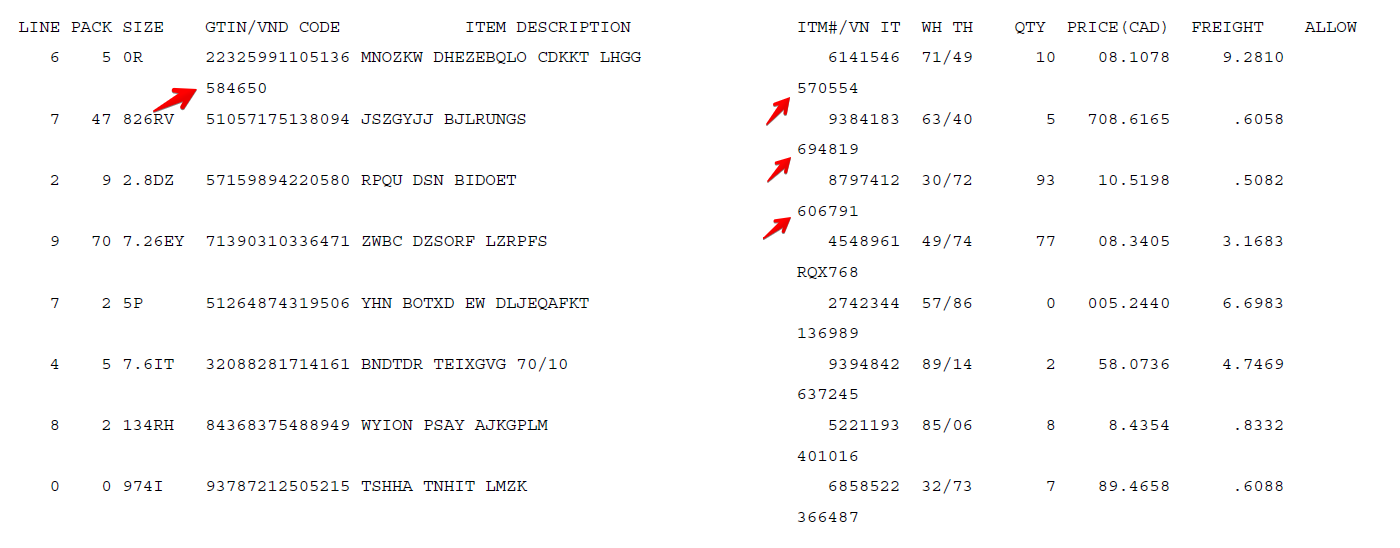
image by author
With only minor inspection you could have missed one important pattern: text at the intersection of some rows and columns is stacked and shifted so that it could hardly be recognized as the additional feature of the same data row.
Nonetheless, any data that does not fit nicely into a column or a row is widely considered unstructured, we can identify this particular real-world phenomenon as semi-structured data.
Which does not make it easier to parse data from a given table for any out-of-box extracting algorithm. While those tools may have reasonably efficient results, in this particular case we require extra development effort to fit your requirements. Moving forward with this tutorial you’ll find a non-trivial solution to this challenge.
#semi-structured-data #pdf #pandas #table #extraction
