**Scikit-learn (sklearn) **is a powerful open source **machine learning library **built on top of the Python programming language. This library contains a lot of efficient tools for machine learning and statistical modeling, including various classification, regression, and clustering algorithms.
In this article, I will show 6 tricks regarding the scikit-learn library to make certain programming practices a bit easier.
1. Generate random dummy data
To generate random ‘dummy’ data, we can make use of the make_classification() function in case of classification data, and make_regression() function in case of regression data. This is very useful in some cases when debugging or when you want to try out certain things on a (small) random data set.
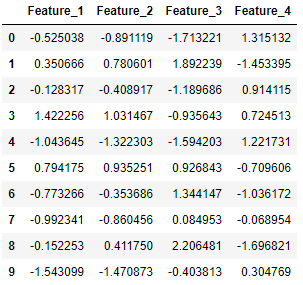
Below, we generate 10 classification data points consisting of 4 features (found in X) and a class label (found in y), where the data points belong to either the negative class (0) or the positive class (1):
from sklearn.datasets import make_classification
import pandas as pd
X, y = make_classification(n_samples=10, n_features=4, n_classes=2, random_state=123)
Here, X consists of the 4 feature columns for the generated data points:
pd.DataFrame(X, columns=['Feature_1', 'Feature_2', 'Feature_3', 'Feature_4'])
And y contains the corresponding label of each data point:
pd.DataFrame(y, columns=['Label'])

2. Impute missing values
Scikit-learn offers multiple ways to impute missing values. Here, we consider two approaches. The SimpleImputer class provides basic strategies for imputing missing values (through the mean or median for example). A more sophisticated approach the KNNImputer class, which provides imputation for filling in missing values using the K-Nearest Neighbors approach. Each missing value is imputed using values from the n_neighbors nearest neighbors that have a value for the particular feature. The values of the neighbors are averaged uniformly or weighted by distance to each neighbor.
Below, we show an example application using both imputation methods:
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import SimpleImputer, KNNImputer
from sklearn.datasets import make_classification
import pandas as pd
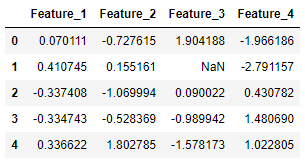
X, y = make_classification(n_samples=5, n_features=4, n_classes=2, random_state=123)
X = pd.DataFrame(X, columns=['Feature_1', 'Feature_2', 'Feature_3', 'Feature_4'])
print(X.iloc[1,2])
2.21298305
Transform X[1, 2] to a missing value:
X.iloc[1, 2] = float('NaN')
X
First we make use of the simple imputer:
imputer_simple = SimpleImputer()
pd.DataFrame(imputer_simple.fit_transform(X))
#machine-learning #data-science #scikit-learn #programming #python #deep learning
