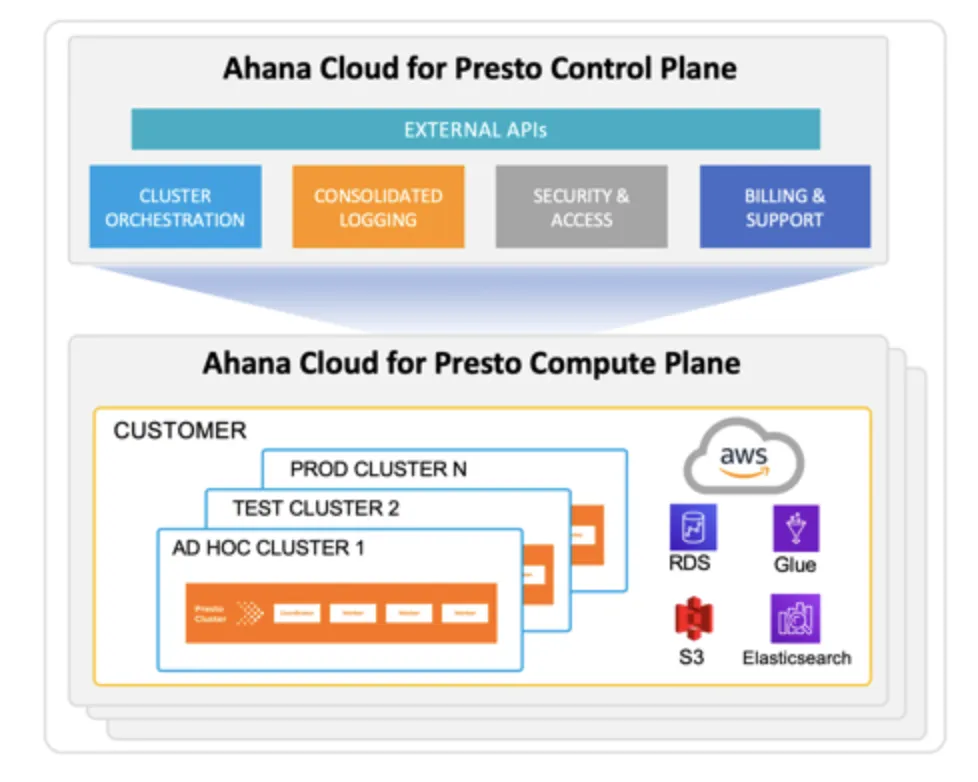
The need for data engineers and analysts to run interactive, ad hoc analytics on large amounts of data continues to grow exponentially. Data platform teams are increasingly using PrestoDB, a federated SQL query engine, to run such analytics across a wide range of data lakes and databases, in-place, without the need to move data.
In this post, we will explore the following:
- The requirements that companies have for self-service ad hoc analytics on data stored in AWS
- How Presto, an open source distributed SQL engine, answers many of these requirements
- How Ahana Cloud, a Presto-as-a-service, built for AWS using Amazon EKS, ECS, and many other Amazon services, enables platform teams to provide self-service analytics for their teams effortlessly.
1. Self-Service SQL Analytics Requirements
As enterprises rely on more AWS services as well as purpose-built databases installed in the cloud, data and metadata are spread very widely. Platform teams have resorted to heavy data pipelining, moving data around across multiple platforms, and in some cases, even creating multiple copies of the data to make the data more accessible. In addition, self-service analytics requires platform engineers to integrate many business intelligence, reporting tools, data science notebooks, and data visualization tools across every data source used.
The obvious downsides are added latency—consumers need to wait longer for those data pipelines to complete and for their tools to be connected–and added costs, since duplicate data consumes additional storage and data movement burns compute cycles. All those platform engineering, management, and monitoring tasks add up. Given the complexity of these activities, platform teams are looking to simplify their approach, and we often see the following requirements from users:
- Query data wherever it lives. While some level of data transformation, cleansing, and wrangling will always be required, users want to eliminate pipelines that simply move data around and remove unnecessary duplicates—with the added bonus of reducing data store proliferation.
- An ANSI SQL engine that works with the widest possible range of tools and data sources, with pre-integrated connectors that are ready to use.
- Ability to query any data in any form, including relational and non-relational sources and object stores, and in any file format, like JSON, Parquet, ORC, RCFile, CSV flat-files and others or Kafka streams.
- Low-latency querying for ad-hoc analysis. With the increase in data-driven analysis for making every decision in the enterprise, users are looking for query results in seconds and minutes–not hours.
- Ability to deal with data of any size, with practically unlimited scalability.
#sql #aws #kubernetes #data analytics #aws cloud #presto #prestodb