Introduction
Some of the most effective drivers of scientific progress are benchmarks. Benchmarks provide a common goal, a purpose, for improving the state-of-the-art on datasets that are available to everyone. Leaderboards additionally add a competitive motivation, offering the opportunity to excel among peers. And rather than just endlessly tinkering to improve relevant metrics, competitions add deadlines that spur researchers to actually get things done.
Within the field of machine learning, benchmarks have been particularly important to stimulate innovation and progress. A new competition, the Efficient Open-Domain Question Answering challenge for NeurIPS 2020, seeks to advance the state-of-the-art in question answering systems. The goal here is to develop a system capable of answering questions without any topic restriction. With all the recent progress in natural language processing, this area has emerged as a benchmark for measuring a system’s capability to read, represent, and retrieve general knowledge.
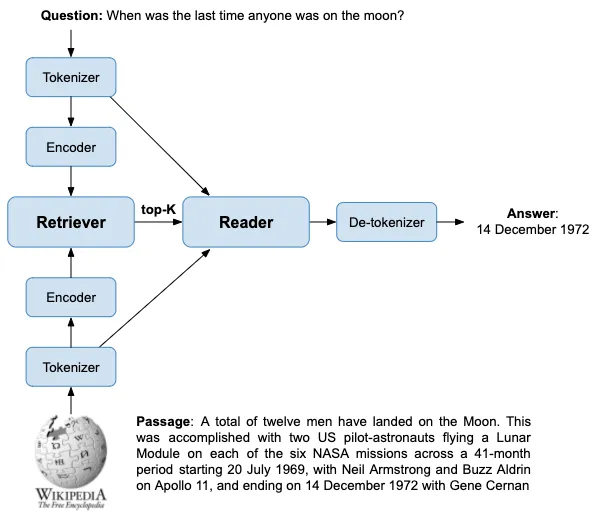
The current retrieval-based state-of-the-art is the Dense Passage Retrieval system, as described in the Dense Passage Retrieval for Open-Domain Question Answering paper. It consists of a set of python scripts, tools, and models developed primarily for research. There are a lot of parts in such a system. These include two BERT-based models for encoding text to embedding vectors, another BERT-based model for extracting answers, approximate nearest-neighbor similarity search and text-based BM25 methods for retrieving candidates, tokenizers, and so on. It’s not trivial to bring such a system to production. We thought it would be interesting to consolidate these different parts and demonstrate how to build an open-domain question-answering serving system with Vespa.ai that achieves state-of-the-art accuracy.
In case you are not familiar with it, Vespa.ai is an engine for low-latency computation over large data sets. It stores and indexes your data so that queries, selection, and processing over the data can be performed efficiently at serving time. Vespa.ai is used for diverse tasks such as search, personalization, recommendation, ads, even finding love, and many other applications requiring computation at query time. It is serving hundreds of thousands of queries per second around the globe at any given time.
Most of the components for a question-answering system are core features in Vespa. A while ago, we improved Vespa’s text search support for term-based retrieval and ranking. We recently added efficient approximate nearest neighbors for semantic, dense vector recall. For hybrid retrieval, Vespa supports many types of machine-learned models, for instance neural networks and decision forests. We have also improved our support for TensorFlow and PyTorch models to run larger NLP and Transformer models.
#nlp #big-data #search #machine-learning #ai