Machine learning can be divided into several categories, where the most popular is supervised and unsupervised learning. Both methods are the two which are very commonly used in the field of data science. **Supervised **learning algorithms are used when all samples in a dataset are completely labeled, while **unsupervised **algorithms are employed to handle dataset without labels at all.
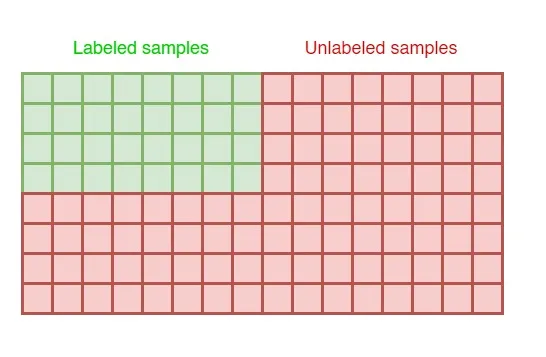
On the other hand, what if we only got partially labeled data? For example, we got a dataset of 10000 samples but only 1500 of them are labeled, while the rest are entirely unlabeled. In such cases, we can utilize what’s so-called as semi-supervised learning method. In this article, we are going to get deeper into the code of one of the simplest semi-supervised algorithm, namely self-learning.
Semi-supervised learning is applicable in a case where we only got partially labeled data.
The self-learning algorithm itself works like this:
- Train the classifier with the existing labeled dataset.
- Predict a portion of samples using the trained classifier.
- Add the predicted data with high confidentiality score into training set.
- Repeat all steps above.
The dataset used in this project is IMDB movie reviews which can easily be downloaded through Keras API. The objective is pretty straightforward: we need to classify whether a text contains positive or negative review. In other words, this problem is just like a sentiment analysis in general. The dataset itself is already separated into train/test, where each of the sets are having unique 25000 review texts.
#ai #nlp #deep-learning #machine-learning #semi-supervised-learning