Objective: Find a neural network model that achieves the highest accuracy rate for the classification of Fruits360 images.
- Deep Feed Forward
- Convolutional Neural Network
- Residual Neural Network (ResNet9)
Data Source: https://www.kaggle.com/moltean/fruits
Full Code Notebook: https://jovian.ml/limyingying2000/fruitsfinal
Data Preparation
First, let’s understand our dataset!
The Kaggle Fruits 360 dataset consists of 90483 images of 131 different types of fruits and vegetables.
To begin, we import the data and the required libraries to run our codes.
import torch
import os
import jovian
import torchvision
import numpy as np
import matplotlib.pyplot as plt
import torch.nn as nn
import torchvision.models as models
import torch.nn.functional as F
from torchvision.datasets import ImageFolder
from torchvision.transforms import ToTensor
from torchvision.utils import make_grid
from torch.utils.data.dataloader import DataLoader
from torch.utils.data import random_split
import torchvision.models as models
%matplotlib inline
Each type of fruits has its unique folder comprising of its jpg images.
Using matplotlib library to display the colour image:
import matplotlib.pyplot as plt
def show_example(img, label):
print('Label: ', dataset.classes[label], "("+str(label)+")")
plt.imshow(img.permute(1, 2, 0))
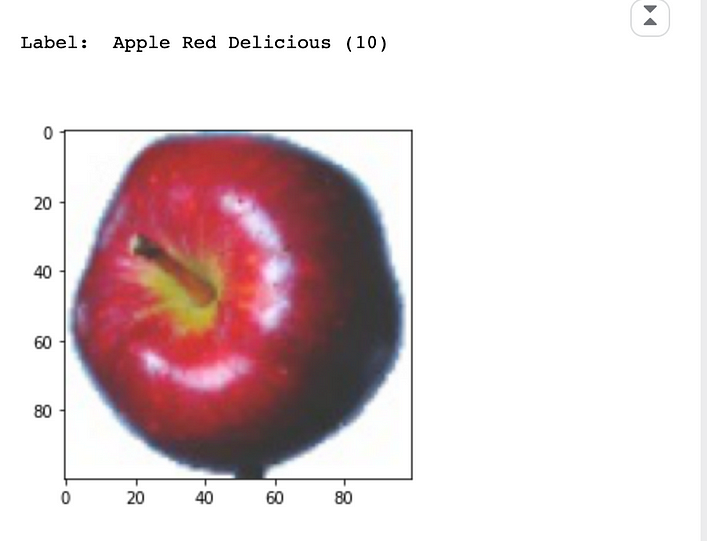
dataset[5000] is an Apple Red Delicious
As we are using PyTorch, we need to convert the above pixel image into a tensor using ToTensor:
dataset = ImageFolder(data_dir + '/Training', transform=ToTensor())
img, label = dataset[0]
print(img.shape, label)
img
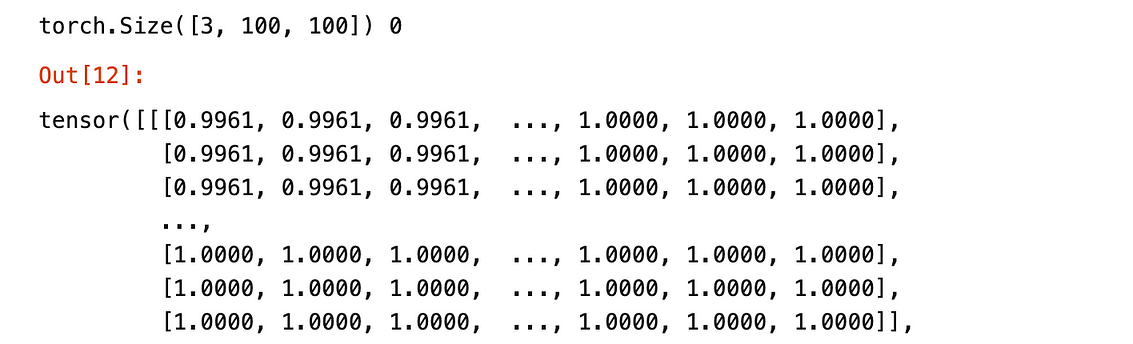
An example of image converted into a tensor
There are 3 channels (red, green, blue) , 100*100 image size. Each value represents the colour intensity with respect to the channel colour.
Training and Validation Dataset
Next, we will randomly split the data to achieve 3 sets of data for different purposes.
- Training Set : Train the model
- Validation Set: Evaluate the model
- Test Set: Report the final accuracy of the model
Size of training dataset : 57, 692
Size of validation dataset: 10, 000
Size of test dataset: 22, 688
Training in Batches
We have a total of 57, 692 training images. We should split our images into smaller batches before training our model using_DataLoader_. Working with a smaller set of data reduces memory space and in turn increases the speed of training.
For our dataset, we will use a batch size of 128.
](https://i.morioh.com/200718/a2941bbf.webp)