Links:
_Paper: _Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics
_Notebook: _https://github.com/eliorc/Medium/blob/master/datamaps.ipynb
A week ago I came across an interesting paper in one of my workplace’s slack channels. Don’t get me wrong, I skim-read through lots of papers, but some really get my attention to go ahead and try them out.
The paper I’m writing about here is the Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics. What I found interesting about this paper is that it challenges the common approach of “the more the merrier” when it comes to training data, and shifts the focus from the quantity of the data to the quality of the data.
In this post, I’ll go over the paper, and finish up with a TensorFlow implementation.
Executive Summary
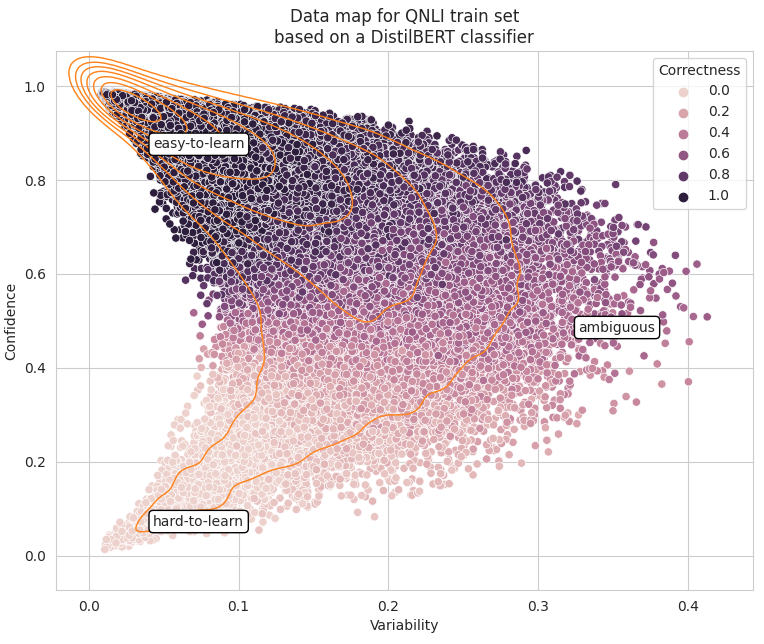
The article innovates by presenting methods to calculate training dynamics (named confidence, variability and correctness), for each sample in the training dataset. Using these we can diagnose our dataset with the aim of distilling the dataset to a smaller sub-set with little to no in-distribution* performance loss and better out-of-distribution* performance — which means better generalization.
This method is agnostic to the type of data, but specific to classifiers optimized by stochastic gradient based methods (basically any classification neural network).
The article continues to explore training dynamics as uncertainty measures and using training dynamics for detecting mislabeled samples. I won’t talk about these two sections in this article.
***In-distribution — **Train/test data are taken from the same distribution
*Out-of-distribution — Train and test come from different distributions
#deep-learning #data-science #dataset #machine-learning