Introduction
The MixUp idea was introduced back in 2018 in this paper and was immediately taken into pipelines by many ML researchers. The implementation of MixUp is really simple, but still it can bring a huge benefit to your model performance.
MixUp can be represented with this simple equation:
newImage = alpha * image1 + (1-alpha) * image2
This _newImage _is simply a blend of 2 images from your training set, it is that simple! So, what will be the target value for the newImage?
newTarget = alpha * target1 + (1-alpha) * target2
The important thing here, is that you don’t always need to One Hot Encode your target vector. In case you are not doing OneHotEncoding, custom loss function will be required. I will explain it deeper in the implementation part.
And here is how the output of the MixUp augmentation can look like. In this case, I took alpha=0.3 and blended together dog and cat images.
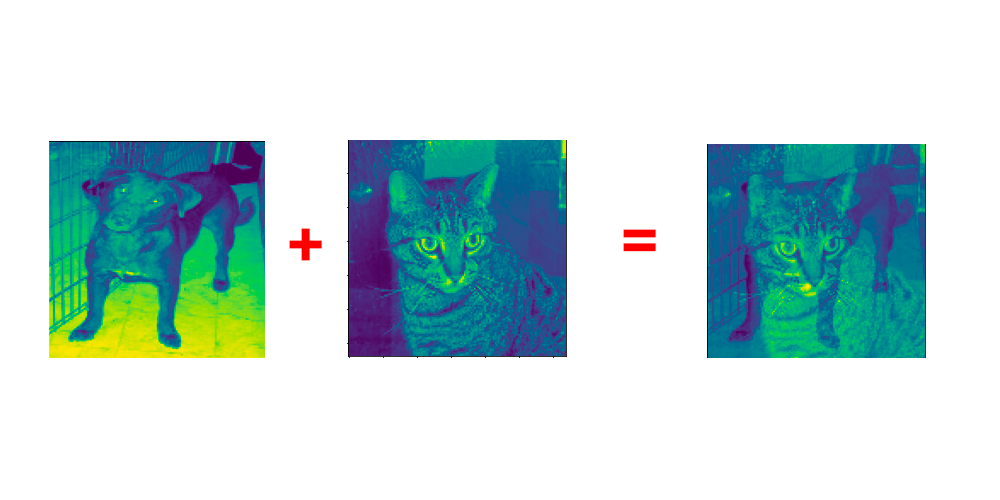
So, why should you try this MixUp idea, if you are still not using it in your augmentation methods?
#machine-learning #data-science #pytorch #python #deep-learning #data science