As an ML engineer or data scientist, sometimes you inevitably find yourself in a situation where you have hundreds of records for one class label and thousands of records for another class label.
Upon training your model you obtain an accuracy above 90%. You then realize that the model is predicting everything as if it’s in the class with the majority of records. Excellent examples of this are fraud detection problems and churn prediction problems, where the majority of the records are in the negative class. What do you do in such a scenario? That will be the focus of this post.
Collect More Data
The most straightforward and obvious thing to do is to collect more data, especially data points on the minority class. This will obviously improve the performance of the model. However, this is not always possible. Apart from the cost one would have to incur, sometimes it’s not feasible to collect more data. For example, in the case of churn prediction and fraud detection, you can’t just wait for more incidences to occur so that you can collect more data.
Consider Metrics Other than Accuracy
Accuracy is not a good way to measure the performance of a model where the class labels are imbalanced. In this case, it’s prudent to consider other metrics such as precision, recall, Area Under the Curve (AUC) — just to mention a few.
Precision measures the ratio of the true positives among all the samples that were predicted as true positives and false positives. For example, out of the number of people our model predicted would churn, how many actually churned?
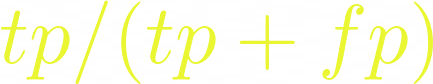
Recall measures the ratio of the true positives from the sum of the true positives and the false negatives. For example, the percentage of people who churned that our model predicted would churn.
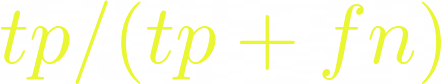
The AUC is obtained from the Receiver Operating Characteristics (ROC) curve. The curve is obtained by plotting the true positive rate against the false positive rate. The false positive rate is obtained by dividing the false positives by the sum of the false positives and the true negatives.
AUC closer to one is better, since it indicates that the model is able to find the true positives.
Machine learning is rapidly moving closer to where data is collected — edge devices. Subscribe to the Fritz AI Newsletter to learn more about this transition and how it can help scale your business.
#programming #heartbeat #data-science-for-ml #artificial-intelligence #data-science #data analysis
