The ‘truth’ should be the data that is being used, not the data in distant storage.
Distribute the data automatically, with the guarantee that all of it will converge on the same ‘truth’.
Use a published open standard for encoding data with its meaning, and communicating changes to it.
Hi, I’m George. This year I left my day job as a software engineering leader and plunged into lockdown under a mountain of work, uncertainty, and risk. Last week, I pushed the button to launch the m-ld Developer Preview. The period between now and when lockdown began has been a mad journey filled with moments of creativity, anxiety, frustration, imposter syndrome, fight and flight urges, elation and time-dilation, and so! much! coffee!
The Why
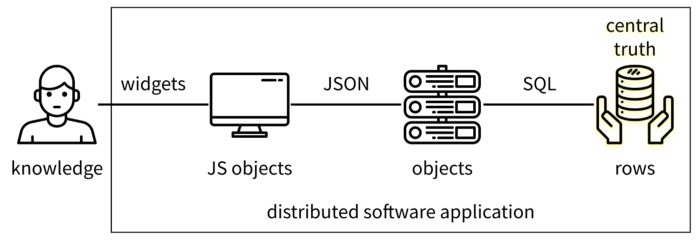
As a data management app developer, I’ve used many ways to encode and store data. Frequently, they are combined in the same architecture with one of the locations becoming known as the ‘central truth’:
While the specific technologies vary, the overall pattern is very common. Motivations include properties of security, integrity, consistency, operational efficiency, and cost. However, there are some other peculiar properties that stand out:
- The ‘truth’ is on the far right-hand side; but the data is being used throughout, with the particular value being realized on the left.
- The software application is responsible for both distributing the data and for operating on it.
- Every encoding syntax is specific to a technology and does not expose the data’s meaning enough to be independently understood.
The main consequence of these properties is application code complexity. We have to be incredibly careful to maintain an understanding of the code as to how current (how close to the truth) our copy of the data is. We must then operate on the data accordingly, and share the understanding with other components. This is hard and frequently goes awry; resulting in software bugs that are very hard to reproduce, let alone fix.
In this blog, I’ll argue that — with recent advances in computer science — we can make improvements to this for many applications. Applying our manifesto, we want our architecture to look more like this:
#collaboration #software #data #decentralization #data-science