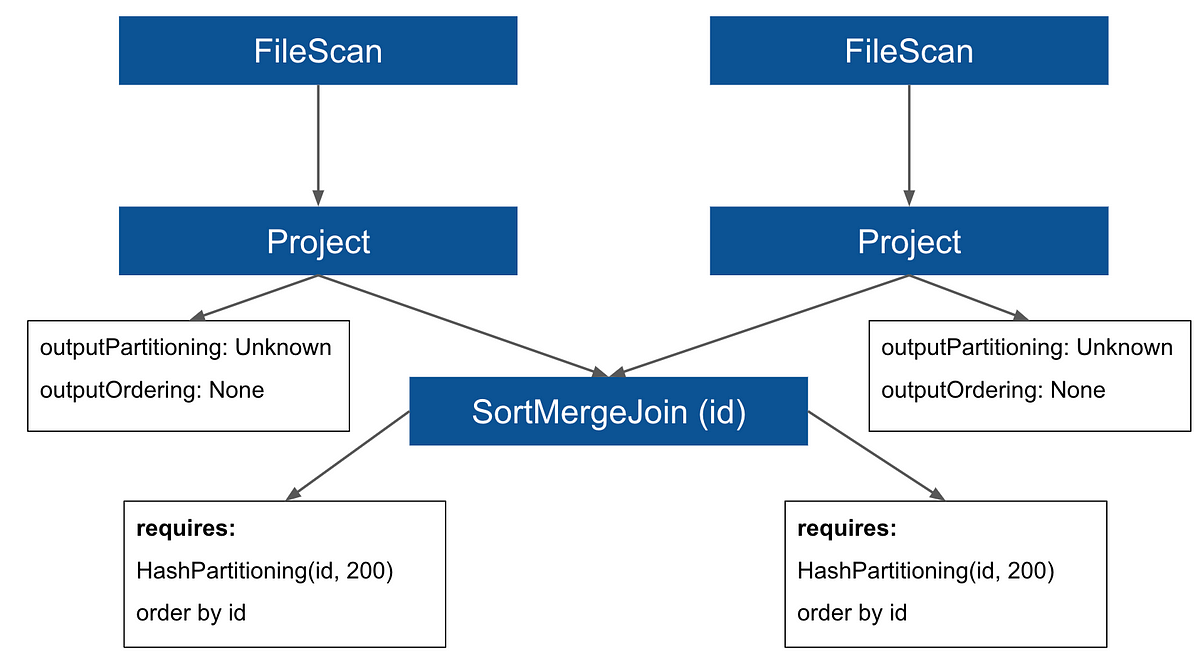
In a distributed environment, having proper data distribution becomes a key tool for boosting performance. In the DataFrame API of Spark SQL, there is a function repartition() that allows controlling the data distribution on the Spark cluster. The efficient usage of the function is however not straightforward because changing the distribution is related to a cost for physical data movement on the cluster nodes (a so-called shuffle).
A general rule of thumb is that using repartition is costly because it will induce shuffle. In this article, we will go further and see that there are situations in which adding one shuffle at the right place will remove two other shuffles so it will make the overall execution more efficient. We will first cover a bit of theory to understand how the information about data distribution is internally utilized in Spark SQL and then we will go over some practical examples where using repartition becomes useful.
#query-optimization #data-engineering #data-science #spark-sql #apache-spark