The main aim of this article is to introduce you to language models, starting with neural machine translation (NMT) and working towards generative language models.
For the purposes of this tutorial, even with limited prior knowledge of NLP or recurrent neural networks (RNNs), you should be able to follow along and catch up with these state-of-the-art language modeling techniques.
Prerequisites
- Basic knowledge of statistics (i.e. you know the basics of concepts like frequency and probability)
- An understanding of word embeddings
- The knowledge and ability to train a normal neural network in PyTorch
Goals:
- Understand the statistical nature of language
- Build a simple neural machine translation system for your native language
- Understand how positional encoding comes about
- Build intuition on how attention mechanisms work
As we all know language is very important to human cognitive reasoning, and to build an intelligent system, language is one of the components that needs to be understood.
But lucky for us, language is statistically structured; or rather, the way words are distributed in a sentence is statistically oriented.
For every language that exists, there are ways in which words in a sentence agree with each other—in the English language ,we call this CONCORD.
What is Concord?
_: the term is defined as the grammatical agreement between two words in a sentence — — by _Richard Nordquist
_: a simultaneous occurrence of two or more musical tones that produces an impression of agreeableness or resolution on a listener — — _Merriam Webstar
Since we aren’t trying to explore the ins and outs of linguistics, we just need a few examples to get the general gist.
Of the two sentences below, which is correct?
- The cats is on the table
- The cats are on the table
Base on the rules of concord (subject-verb agreement), the second statement is correct. Since the subject is plural, the verb must also be plural.
However, we have different rules that guide the use of words in different languages. But the major idea is that whenever a particular word is used in a sentence, there is a particular word that is frequently used after it. For example, whenever the word **The **appears, it’s usually followed by a noun.
This concept—how a word is frequently used after another word—can aid in the statistical modeling of language.
With this basic intuition, you can say then that it’s easier to build a system that models language without the use of deep learning. We could just build a system that keeps a statistical record—i.e the frequency with which each word follows another, and extract a result from that system.
If you want to know a bit more about this concept and how it applies to language modeling, check out the following post (but I’d suggest reading this article first before moving to this one):
RNN From First Principles(Bayes can do what rnn can do)
While this is a start, such a system does not capture the full statistical nature of language. We need a system that can learn these rules on its own and build intuition by itself without explicit teaching.
To build such a system that learns the rules of grammar and language representation without explicit teaching or hardcoding comes the need for neural models using deep learning techniques.
Deep Learning and Neural Machine Translation
In deep learning, when it comes to NMT, we use a neural network architecture known as a recurrent neural network to model language sequences.
What’s a sequence? Using both the English and mathematical definitions we can capture the meaning:
a particular order in which related things follow each other — English
Here we have the literal meaning. Language is a sequence, music is a sequence—put another way, there’s an order to which you arrange musical notes to form a perfect rhythm, and the same thing applies to words.
And here’s the mathematical definition from Wikipedia:
In mathematics, a sequence is an enumerated collection of objects in which repetitions are allowed and order does matter.
But we can’t simply pass words into an RNN and expect it to work its magic. Essentially, computers don’t understand any of this gibberish we humans use.
Computers deal with numbers—they don’t see images, nor do they see the words you type.
So for us to interact with the computer, we need to give it what it understands. For this task, each word will be represented by a number.
For example, let’s the same example as before: The cats are on the table.
For us to convert it to a form the model will accept, we can let:
- 1 represents
the - 5 represents
cats - 3 represents
are - 4 represents
on - 6 represents
table
It’s important to note that we picked these numbers just by guessing at random. Hence, the sentence “The cats are on the table” is now represented by a list of numbers **[1,5,3,4,1,6]**.
If you’ll recall, earlier I mentioned that we can’t just build a system that uses merely the frequency of how words follow each other to model language. Such a statistical system would not be detailed enough.
For example, the system takes the form of P(X| Y). This is interpreted as, given a word Y, what’s the probability of word X coming next. If we assume the word Y to be “the”,then the probability of a noun following it will be very high, and the probability of a verb will be very low.
But such a model isn’t good enough for our aim—we want a model that captures things we can’t see and understands patterns.
This is where the RNN architecture comes into play. Specifically, it includes a learnable parameter to the probability function P(X|Y). This learnable parameter learns everything that needs to be known.
The parameter is called state **h. **Some call it memory. It describes the state of the previous sequence. You can think of it as keeping what the previous sequence is all about.
Hence, the RNN is using the state and the previous input to determine the next output:
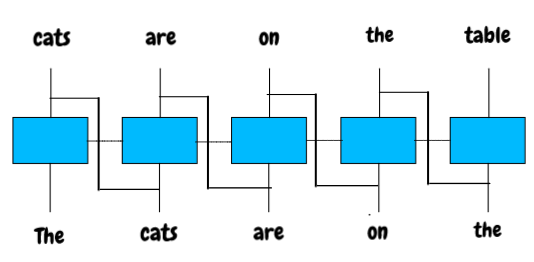
Let the blue box represent P(X|Y). Hence, if we take the first sequence The, the model will look like this P(Cats | The).
The model does the same for all other words. For example, P(on|The)will be very low**.**
Based on the option that gives the highest probability, we get our output, which is Cats—but where does the **h **call state come in?
Well, at the initial stage state **h **will be zero, given that the model has no prior information. That is, the initial stage is P(Cats |The, h=0), but after the initial stage, state h now has some information to store.
We don’t discard the state h; instead, we pass it to the next computation of the model on the next sequence input—that’s what the line connecting the blue box in the image above does.
Then the next computation will look like this: P(are | Cats, The, ht-1). In this case_, _we use the previous state and the previous word to compute the next output.
The shared state h makes it possible for the model to understand the language better than the simple statistical model I discussed before.
To learn more about RNN with a graphical illustration check out this post on Towards Data Science:
Illustrated Guide to Recurrent Neural Networks
Machine learning is rapidly moving closer to where data is collected — edge devices. Subscribe to the Fritz AI Newsletter to learn more about this transition and how it can help scale your business.
The intuition behind sequence-to-sequence (seq2seq) with RNN
If language (words, sentences) is a sequence, then what do we call the translation of one language to another? We call it sequence-to-sequence (seq2seq).
The main aim of this modeling technique is to have a function f that takes in a word in a language X and output the corresponding word in the other language Y.
Let’s say we have a language in which the word human is the same as the word animal. We want a function that takes in the word human and outputs the word animal…f(“human”) = “animal”.
We could try to use our simple statistical model, but we now know it won’t be able to capture the desired patterns. Language is more complex than the way it’s described in basic terms.
For example, some words can have different meanings based on various contexts, and there are some languages in which words of the same spelling have multiple and different meanings based on their **diacritics **(signs or accent marks on words indicating different pronunciations).
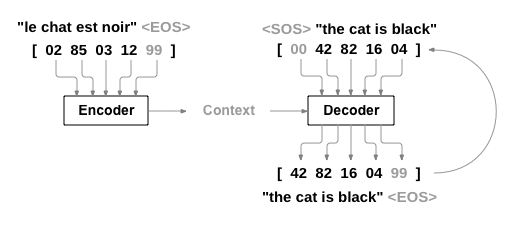
PyTorch seq2seq tutorial
So how do we build an effective system that translates words from one language to another?
The image above describes it all. We need to build what’s known as an encoder-decoder model.
#heartbeat #naturallanguageprocessing #transformers #deep-learning #machine-translation #deep learning
