Deep learning models are becoming heavier day by day, and apart from training them faster, a lot of focus is also around faster inference for real time use-cases on IOT/ Edge devices. So around 2 years back Intel released OpenVINO toolkit for optimizing inference of Deep Learning models on Intel’s hardware.
To know all basics around OpenVINO, Ihave divided this post into 3 sections and depending on your interest you can switch to any one of the below:
- **What **is OpenVINO
- **_Why/ When _**OpenVINO
- **_How _**to Build & Run a toy NN on OpenVINO
What is OpenVINO
Intel’s** Open** Visual Inference and Neural network Optimization (OpenVINO) toolkit enables the vision application (or any other DNN) to run faster on Intel’s Processors/ Hardware.
The OpenVINO™ toolkit is a comprehensive toolkit for quickly developing applications and solutions that emulate human vision. Based on Convolutional Neural Networks (CNNs), the toolkit extends CV workloads across Intel® hardware, maximizing performance.
To put it straight, an attempt by Intel to sell their underlying processors (CPUs, iGPUs, VPUs, Gaussian & Neural Accelerators, and FPGAs) for making your AI (vision) Applications run faster.
This is not a toolkit for faster training of your Deep Learning task, but for faster inference of your already trained Deep Neural model.
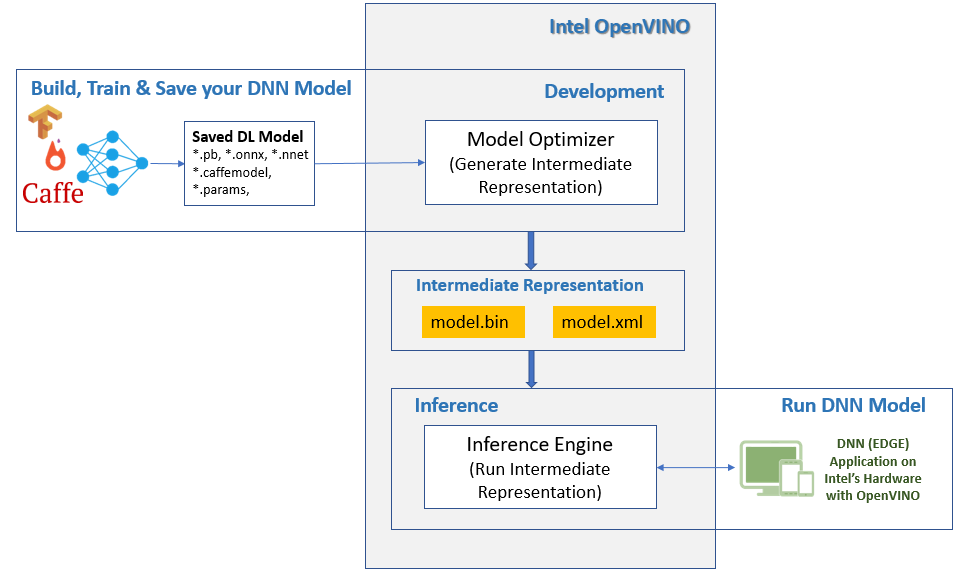
The tool main components of OpenVINO toolkit are
For complete details on the toolkit, check this.

Intel OpenVINO, Source
The task of the Model optimizer (a .py file for individual frameworks) is to take a already trained DL model and adjust it for optimal execution for the target device. The output of Model Optimizer is the Intermediate Representation (IR) of your DL Model.
The IR is set of 2 file which describes the Optimized version of your DL model
*.xml- Describes the network topology*.bin- Contains the weights (& biases) binary data
The output of Model Optimizer (IR files), is what we must pass to Inference Engine, which runs it on your hardware.
So to make best use of your Intel Hardware for your ML (Edge, cloud …) applications running in production, all you need to do is, generate the IR files of your DL model and run it on the Inference Engine rather than directly running it over the hardware.
Why/ When OpenVINO
As mentioned above a lot of Edge/ Cloud applications are already using more advanced Intel hardware/ processors/ architectures.
So one of the most important reason why one would want to shift to OpenVINO is to make best use of the underlying Intel Hardware.
Apart from this I have seen a lot of Application Development teams shifting to OpenVINO just for Intel’s already optimized Pretrained models for their Edge Applications
Pretrained Models for the Intel® Distribution of OpenVINO™ Toolkit
Opencv/open_model_zoo
So all you are required to do is, download the IR files for one of the pretrained model and just use it with Inference engine for your end application.
The main disadvantage for such pretrained models is when required, re-training these models with your costume data is not always easy, as not everything is well documented around re-training/ fine-tunning for all provided models.
And if you are thinking to use one of the TF model Zoo (or similar for other DL frameworks) or building/ train your own custom Tensorflow (or PyTorch etc…) models and expect that it would be easy (or even possible every time) to convert it to the required IR files, that would not be the case always.
So it becomes really important while deciding to port any of your applications to OpenVINO to do a quick check of below points:
- If you start with the IR files, you also have proper understanding/ documentation for re-training the model behind the provided IR files
- If you are building your own DNN model, you can convert your model architecture (though not trained yet) to IR using Model Optimizer
As you long as you are good with both the points above, you should be fine choosing OpenVINO for your DL Application, but if not, you might want to reassess your decision.
#edge-computing #openvino #deep-learning #intel #deep learning