Welcome to some practical explanations to Apache Spark with Scala. There is even **_Python supported Spark is available which is PySpark. _**For the sake of this post, I am continuing with Scala with my windows Apache Spark installation.
- Spark Shell
- Go to the Spark installation directory and cd to bin folder. type spark-shell, enter. You will see Spark Session being started and showing some logs which are very important.
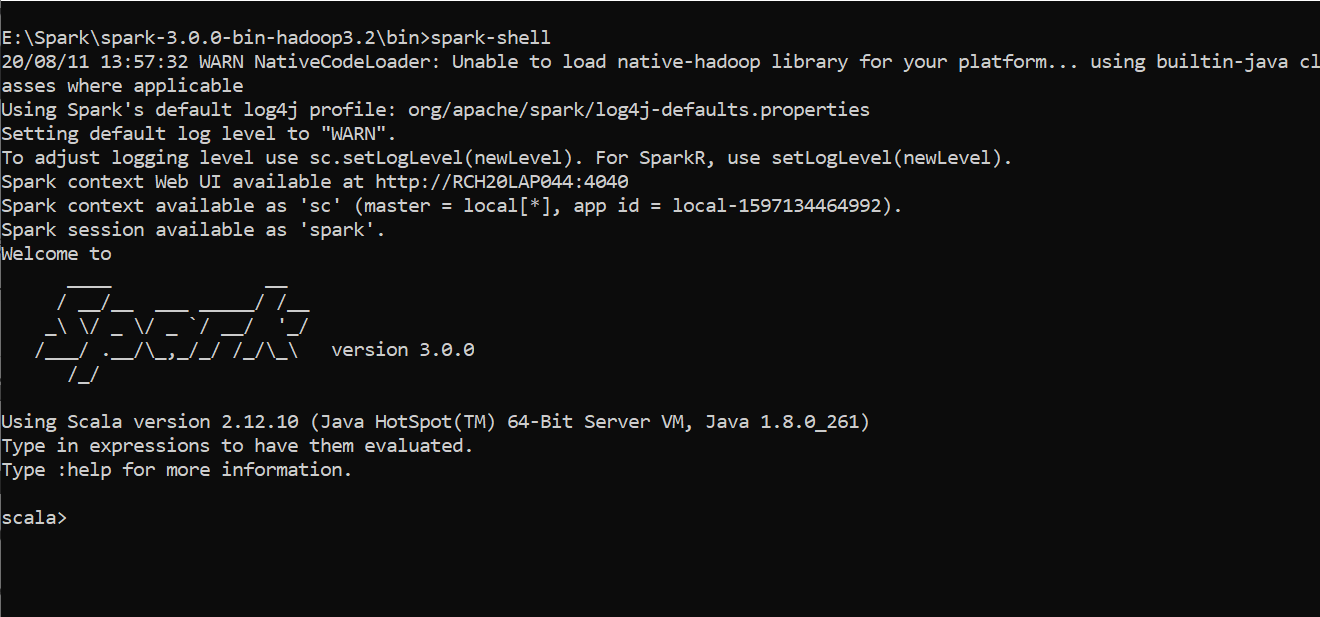
Initialization of Spark Shell
spark-shell_ command provides a simple way to learn the Spark API, as well as a powerful tool to analyze data interactively. _It is available in either Scala or Python
Let’s discuss some terms logged for spark-shell command.
SparkContext(sc) is the entry point for Spark functionality. A Spark Context represents the connection to a Spark cluster and can be used to create RDDs in the cluster. Only one SparkContext should be active per JVM. All about Sparck Context constructors and Methods can be found here official link**.**SparkSession(spark) is the entry to programming Spark with the Dataset and DataFrame API. It is one of the very first objects you create while developing a Spark SQL application- We can see the Spark UI from http://rch20lap044:4040/jobs/. This address can be different for each system. This UI gives all the details about the currently running job, storage details, Executors details, and more.
Spark-Shell Commands:
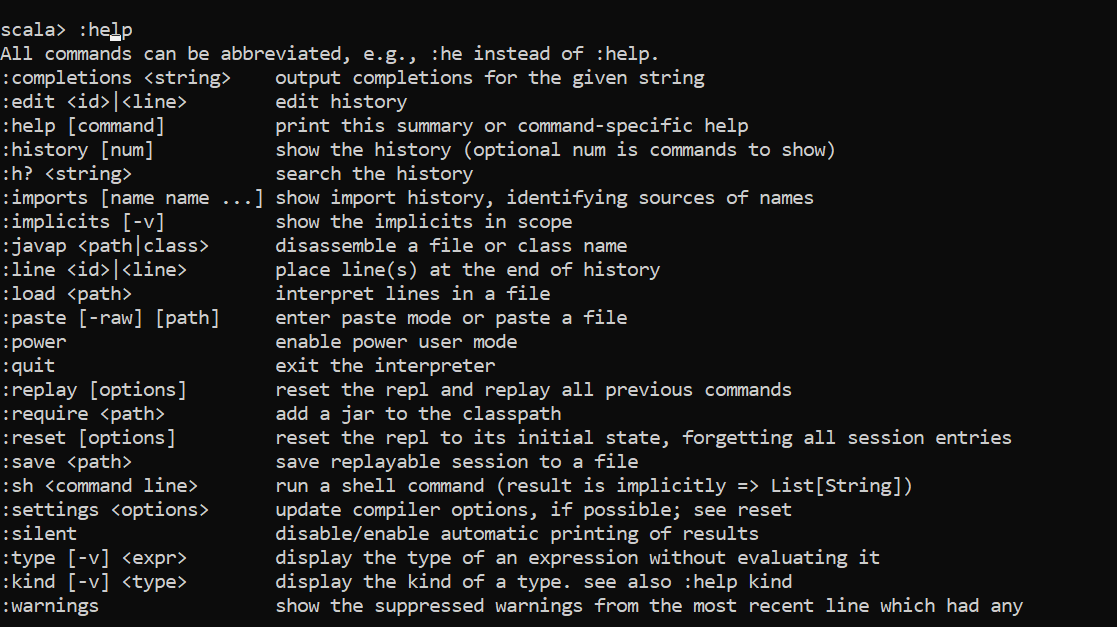
- :help
- Prints all the options available given by spark-shell.
#scala #big-data #apache-spark #apache-spark-rdd

1.40 GEEK