Humans have a lot of senses, and yet our sensory experiences are typically dominated by vision. With that in mind, perhaps it is unsurprising that the vanguard of modern machine learning has been led by computer vision tasks. Likewise, when humans want to communicate or receive information, the most ubiquitous and natural avenue they use is language. Language can be conveyed by spoken and written words, gestures, or some combination of modalities, but for the purposes of this article we’ll focus on the written word (although many of the lessons here overlap with verbal speech as well).
Over the years we’ve seen the field of natural language processing (aka NLP, not to be confused with that NLP) with deep neural networks follow closely on the heels of progress in deep learning for computer vision. With the advent of pre-trained generalized language models, we now have methods for transfer learning to new tasks with massive pre-trained models like GPT-2, BERT, and ELMO. These and similar models are doing real work in the world, both as a matter of everyday course (translation, transcription, etc.), and discovery at the frontiers of scientific knowledge (e.g. predicting advances in material science from publication text [pdf]).
Mastery of language both foreign and native has long been considered an indicator of learned individuals; an exceptional writer or a person that understands multiple languages with good fluency is held in high-esteem, and is expected to be intelligent in other areas as well. Mastering any language to native-level fluency is difficult, imparting an elegant style and/or exceptional clarity even more so. But even typical human proficiency demonstrates an impressive ability to parse complex messages while deciphering substantial coding variations across context, slang, dialects, and the unshakeable confounders of language understanding: sarcasm and satire.
Understanding language remains a hard problem, and despite widespread use in many areas, the challenge of language understanding with machines still presents plenty of unsolved problems. Consider the following ambiguous and strange word or phrase pairs. Ostensibly the members of each pair have the same meaning, but undoubtedly convey distinct nuance. For many of us the only nuance may be a disregard for precision of grammar and language, but refusing to acknowledge common use meanings mostly makes a language model look foolish.
Couldn’t care less = (?)Could care less
Irregardless= (?)Regardless
Literally = (?)Figuratively
Dynamical= (?)Dynamic
Primer: Generalization and Transfer Learning
Much of the modern success of deep learning has been due to the utility of transfer learning. Transfer learning allows practitioners to leverage a model’s previous training experience to more quickly learn a novel task. With the raw parameter counts and computational requirements of training state of the art deep networks, transfer learning is essential for the accessibility and efficiency of deep learning in practice. If you are already familiar with the concept of transfer learning, skip ahead to the next section to have a look at the succession of deep NLP models over time.
Transfer learning is a process of fine-tuning: rather than training an entire model from scratch, re-training only those parts of the model which are task-specific can save time and energy of both computational and engineering resources. This is the “don’t be a hero” mentality espoused by Andrej Karpathy, Jeremy Howard, and many others in the deep learning community.
Fundamentally, transfer learning involves retaining the low-level, generic components of a model while only re-training those parts of the model that are specialized. It’s also sometimes advantageous to train the entire pre-trained model after only re-initializing a few task-specific layers.
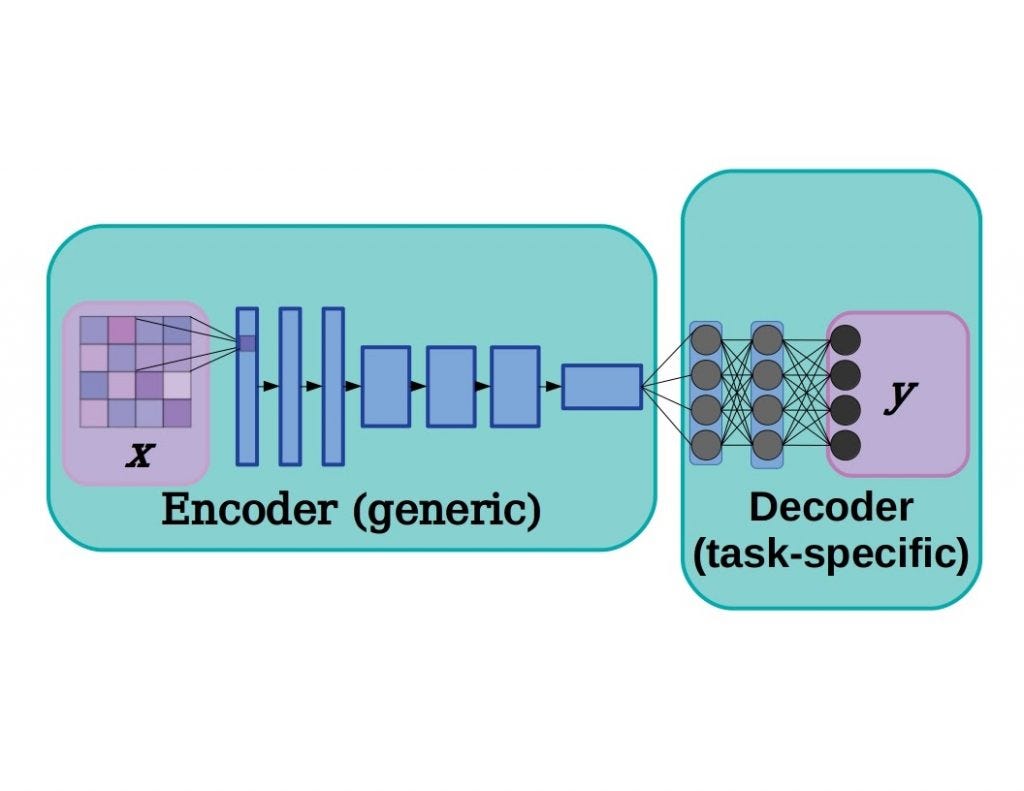
A deep neural network can typically be separated into two sections: an encoder, or feature extractor, that learns to recognize low-level features, and a decoder which transforms those features to a desired output. This cartoon example is based on a simplified network for processing images, with the encoder made up of convolutional layers and the decoder consisting of a few fully connected layers, but the same concept can easily be applied to natural language processing as well.
In deep learning models there is often a distinction between the encoder, a stack of layers that mainly learns to extract low-level features, and the decoder, the portion of the model that transforms the feature output from the encoder into classifications, pixel segmentations, next-time-step predictions, and so on. Taking a pre-trained model and initializing and re-training a new decoder can achieve state-of-the-art performance in far less training time. This is because lower-level layers tend to learn the most generic features, characteristics like edges, points, and ripples in images (i.e. Gabor filters in image models). In practice, choosing the cutoff between encoder and decoder is more art than science, but see Yosinki et al. 2014 where researchers quantified the transferability of features at different layers.
#artificial-intelligence #deep-learning #ai #neural-networks #deep learning